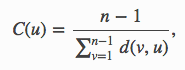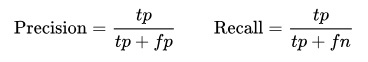|By Lingjun (Ivan) Chen and Nuo (Nora) Xu|
Problem Statement
Nowadays, personalized recommendation systems are implemented by many online businesses, which try to identify user’s specific tastes then provide them with relevant products to enhance user’s experience. Users, in turn, would be able to enjoy the convenience of exploring what they potentially like with ease and are often surprised by how good the recommended results are. However, mainstream restaurant recommendation apps have not adopted personalized restaurants recommenders generally. Therefore, finding an ideal restaurant is always a struggle for newcomers and sometimes even for local people, who are looking for places new and exciting to go. Inspired by such a challenge, we aim to build a personalized restaurant recommender system prototype that not only considers the interactions (visits) between customers and restaurants, but also incorporates metadata (side information) that expresses both the customer’s personal tastes and restaurants’ features. Such approach can increase each user’s experience of exploring and finding restaurants that are closer to their tastes. We used datasets provided by Yelp and a package named LightFM, which is a python library for recommendation engines to build our own restaurant recommender.
Here is an introductory article to refresh on some of the basic ideas and jargon on recommender systems before proceeding.
Github repository of LightFM: https://github.com/lyst/lightfm
Github repository for our model: https://github.com/Ivanclj/Yelp-Recommender
Background
When implementing recommender systems, researchers generally adopt two methods: Content-Based Filtering (CBF) and Collaborative Filtering (CF). CBF models users’ tastes based upon their past behaviors, but does not benefit from data on other users. On the contrary, CF looks at user/item interactions (visits) and tries to find similarities among users or items to do the recommender job. However, both methods have their limitations. A CBF-based system is limited by novelty in recommended results. Because it only looks at user’s past history, it never jumps to other areas that users might like but have not interacted with before. Additionally, if the quality of content does not contain enough information to discriminate the items precisely, CBF will perform poorly. On the other hand, CF suffers from sparse interaction matrix between users and items, where many users have very few interactions or even no interactions at all. This is also known as the cold start problem, which would be a huge problem especially for newcomers to certain areas to find suitable restaurants. To tackle this problem, we aim to develop a hybrid approach, which leverages both the collaborative information between users and items and user/item metadata to complete the recommendation job.
Dataset
We used three datasets in this project: business.json, review.json, and user.json. Dataset business contains geographical information about 192,609 businesses, categories and attributes, such as average star rating, hours, whether they offer parking and etc. Dataset review includes 6,685,900 review texts and ratings users write to businesses. Dataset user includes information like how long ago the user has joined Yelp, the number of reviews he/she has written, the number of specific compliments received, and his/her friend mapping on Yelp about 1,637,138 users. The three datasets can be merged by unique keys user_id and business_id. More detailed explanation of the data can be found in Yelp documentation (Source: https://www.yelp.com/dataset).
Data Cleaning & Feature Engineering
To build a hybrid recommender system, we would need an interaction matrix between users and items, metadata of restaurants that summarize their characteristics, and metadata associated with customers that indicate their taste preference.
Business dataset includes businesses of all categories from over 100 cities. For the reason that items (restaurants) in different cities have few interactions with each other, we filtered the dataset to keep only the city with the highest number of restaurants — Toronto (10,093 restaurants). Then we moved forward, exploring restaurant attributes that would potentially be useful in recommenders. Most features have many missing values across restaurants so we picked number of stars the restaurant was rated (0-5 scale), review counts of the restaurants, and the categories of the restaurants as item features. Usually each item (restaurant) has an average of 10 categories/tags assigned by Yelp, and there are 436 tags in total across all restaurants, such as seafood, vegetarian, breakfast & brunch, bars and so on. We decided to select top 60 tags with highest popularities since including some tags that only appear a few times out of more than 10k restaurants would add more noise in the recommender. Furthermore, we calculated TF-IDF (term frequency-inverse document frequency) values for each tag (Figure 2), which would be used as weights in model fitting later. We applied TF-IDF instead of binary value for the purpose of promoting core tags over incidental ones, and giving higher weight to tags that appear less frequently.

In review dataset, we found that there were cases where a unique user would rate one restaurant several times throughout his/her history. For such case, we only kept the most recent review since it reflected the user’s latest preference.
In order to remove user bias from subjective rating (some users rated a high score for every restaurant), we centered those users’ rating by subtracting their mean rating, and converted the results to 1 if positive and -1 if negative. The unrated items were kept as 0. The reasoning for this transformation is that we want to focus more on ranking the user liked restaurants and disliked restaurants in the correct order, rather than predicting user ratings on each restaurant, which would result in high variance over time.
The final step of data cleaning was to select out characteristics of users. We heuristically chose four features that are not sparse, which are number of reviews wrote, number of times reviews are regarded as useful, whether the user is active/elite in Yelp and most importantly, user’s favorite restaurant category from past interactions.
Evaluation Metric
In terms of the evaluation of recommenders, we decided to choose AUC (area under the curve) over RMSE (Root Mean Square Error) that was the most frequently used metric for measuring explicit recommendation system performance. RMSE emphasizes accuracy of rating prediction, which is how much customers like or dislike each recommended item. On the other hand, AUC is a decision-support metric that cares only whether customers like the item or not. In our case, figuring out customer preference in general is more important and practical than predicting their rating for each restaurant; therefore AUC is used in results evaluation below.
To explain the concept briefly, AUC is the area under the curve of ROC (receiver operating characteristic) that plots true positive rate against false positive rate with the increasing of recommendation set size. True positive rate (TPR) is the ratio of recommended items that users like to the total number of favored items, while false positive rate (FPR) is the ratio of recommended items that users dislike to the total number of unfavored items, as shown in Figure 3.

Additionally, we calculated precision at k scores for each user in the test set. Precision at k score measures the fraction of known positives in the first k positions of the recommended list. A perfect score is 1.0. We chose k = 5 in our setting but k could be any arbitrary number depends on how many items need to be shown at a time.
Methodology
1. Baseline Model
First off, we started with a baseline method. The underlying algorithm is to recommend items (restaurants) that are either popular or have high rating scores, regardless of features of items or feedback from the users. This method is useful for cold start (new customers) scenarios where limited information of the user or item is known. To implement the baseline model in Yelp data, we sorted restaurants by number of reviews and ratings in descending order, and then treated top k as a recommended list indiscriminately for all customers.

Figure 4 illustrates that AUC value of the plot above is very close to 0.5. This results infers that given a recommended restaurant, a random user has a 50% chance of liking it. Unsurprisingly, the baseline method performed poorly and therefore, a more sophisticated model is needed.
2. LightFM Model:
a. Matrix Factorization
LightFM incorporates matrix factorization model, which decomposes the interaction matrix into two matrices (user and item), such that when you multiply them you retain the original interaction matrix. Figure 5 illustrates this notion graphically. The factorized matrices are known as user and item embeddings, which have the same number or rows (latent vector dimension) but different number of columns depending on the size of the users or items.

The latent embeddings could capture latent features about attributes of users and items, which represent their tastes. For example, people who like Asian restaurants would have similar embeddings with those that prefer Chinese restaurants but are probably further away from those that are fond of Mexican food in the vector space. An embedding is estimated for every feature, and embeddings across all features sum up to arrive at representations for users and items. Figure 6 shows the formula of how features are summed.

b. Loss Function
LightFM implements four loss functions for different scenarios. They are logistic loss, BPR (Bayesian Personalized Ranking pairwise loss), WARP (Weighted Approximate-Rank pairwise loss) and k-OS WARP, which are all well documented in the LightFM package.
BPR and WARP are special loss functions that belong to a method named Learning to Rank and are originated from information retrieval theory. The main idea of BPR is sampling positive and negative items, then running pairwise comparisons. It first selects a user u and then a random item i which user u views as positive. Then it randomly selects an item j which user u views as negative. After it has both samples, it calculates the predicted score for both items by calculating the dot product of the user and item factorized matrices. Next, it calculates the difference between two predicted scores and then passes this difference through a sigmoid function and uses it as a weighting to update all of the model parameters via stochastic gradient descent. In this way, we completely disregarded how well we predict the rating for each user-item pair and focused only on the relative ranking between items for a user instead.
WARP works in similar fashion as it deals with triplet loss (user, positive item, negative item) like BPR. However, unlike BPR that updates parameters for every iteration, WARP only updates parameters when the model predicts the negative item has a higher score than the positive item. If not, WARP keeps on drawing negative samples until it finds a rank violation or hits some threshold for trying. Besides, WARP makes a larger gradient update if a violating negative example is found at the first try, which indicates that many negative items are ranked higher than positives items given the current state of the model. Or WARP makes a smaller update if it takes many sampling to find a violating example, which infers the model is likely to be close to the optimum and should be updated at a low rate.
Generally, WARP performs a lot better than BPR. However, WARP takes more time to train since if the rank is not violated, it keeps on sampling negative samples until a violation happens. Moreover, as more epochs (iterations) are trained, WARP becomes slower as we can seen in Figure 7. This phenomenon is because a violation becomes more difficult to find. Thus, setting a cutoff value for searching is essential for training with WARP loss.

We compared models across logistic, BRR and WARP to find the best loss for our models.
c. Model Establishment
i. Pure Collaborative Filtering
Pure CF model is achieved by LightFM if only passes in the interaction matrix to fit the model. This ensures that the model has access only to the interaction information but no other metadata information. We split the data into train and test, with 20% interactions (82,127) in test and 80% (328,507) interactions in train and checked that the two sets were fully disjointed. Next, we initialized random parameters to fit the model using three different losses (logistic, BPR, WARP). However, since our parameters are randomly chosen, it was necessary to perform hyperparameters search to obtain the best model. To do that, we utilized the scikit-optimizer package to search through a range of values for different hyperparameters and evaluated them on mean AUC score. Outputs are shown in Figure 8 and Figure 9.


ii. Hybrid Matrix Factorization
At this stage, we were fitting the hybrid model that not only takes in interaction matrix, but also item features and user features as well.
Item features is a matrix with dimension 10093 x 10156, which is the number of items times number of item features. The number of item features equals to 10156 for the reason that LightFM internally creates a unique feature for each item in addition to other features. So 10156 = 10093 (unique feature) + restaurant stars + review count + 61 tags. Since LightFM normalizes each row in the item features to have its sum to 1, some of the features such as review count, which have very large values, could potentially dominate the weight assigned. To account for that, we normalized some features with large values by taking the log value and then dividing by their max. The same procedure was applied to build the user features matrix (92,381 x 92,420). We also added user alpha and item alpha into the model as regularization parameters to control overfitting. Hyperparameter search for the hybrid model was then performed. Outputs are shown in Figure 10 and Figure 11.


Result
1. Model Evaluation
a. AUC score
Figure 12 shows the results of mean AUC score across all users in a test set of the models with different losses and trials. These results are based upon optimal hyperparameters for each model through scikit-optimizer library, which performs cross-validation to find the best set of parameters. Multiple trials were run to account for random noises.

As we can see, WARP performs best both in a pure CF setting as well as a hybrid setting. Logistic loss seems to perform worse when metadata is included while all learning to rank method performs better in a hybrid setting. BPR seems to fit the training set very well but performs poorly when generalized to the test set, indicating a problem with overfitting even after tuning for optimal parameters.
b. Precision at 5
Figure 13 shows the results of mean precision at 5 score across all users in the test set of the models with different losses and trials right after calculating AUC so they are from the same model within each setting. Precision at 5 score has similar results with AUC where WARP performs best out of three losses. The number are relatively low since most users in the test set has a few interactions (cold start users), so most top 5 recommended items by the model are the ones that they have not interacted with, which resulted in very low precision overall. Since our goal was to optimize AUC, we focused on making sure positive items were placed before negative but the order of positive items with interactions were not necessarily placed in front. So we should only compare the relative difference between these scores instead of their magnitude.

2. Recommendation Demo
Figure 14 and Figure 15 are demos for recommendation on random users. “Known positives” are restaurants that the specific user went to and had positive interactions with. “Recommended” are the top k (k = 5 in this case) restaurants recommended for this user.
Figure 14 demonstrates a classical cold start case where user 66 has only one positive interaction but we are trying to recommend 5 to him/her. So precision would be low but we can see Japanese and Thai restaurants are recommended as it is close to the known positive, which this user had interaction with. There are also Ice cream and Brunch places recommended, which we suspect is either from the collaborative information or other metadata such as stars and review counts of the restaurant. For user 74, out of 5 recommended results, the user had positive interaction with 2 of them so the precision at 5 = ⅖ = 0.4, as shown in Figure 15.


The sample recommendation function is a particularly useful tool because it lets you do some eye tests on the recommendation results. In this case, we printed out the categories of restaurants to compare, but one can also print out restaurant stars or review counts to see if it makes more sense.
3. Tag Similarity
Another great feature from LightFM is that the estimated item embeddings can actually capture the semantic characteristics of the tags. Instead of driving by textual corpus coincidence statistics like word2vec does, the way LightFM finds similar tags is purely based on interaction data. These features are useful in terms of applying collaborative tagging for new restaurants, group tags into bigger categories, and providing justification for the recommender system. From Figure 16, we can see that most tags recommended share semantic similarity with target tags indeed.

Conclusion & Next Step
In this paper, we explored the potentials of adopting a hybrid approach to build a personalized restaurant recommender system using Yelp’s dataset and LightFM package. We also compared its performance with a pure collaborative filtering model and with different loss functions implemented in the packages. In addition to just basic interaction information between items and users in pure collaborative filtering, the hybrid recommendation system also utilizes item & user metadata, which makes it perform better in the learning-to-rank setting (as shown above) and more robust to cold-start problems.
As for next step, it will be easy to quickly expand the scope of our project to include more cities into the recommender system. For now our recommender aims only at users in Toronto, but it could be applied to all locations if needed as long as information on users and items are available. Considering further optimizing of the system, we suggest including more features, such as demographic data of users and geohash of restaurants, with the hope that more variation could be explained. In addition, manipulating the tags of items for higher inclusiveness and lower overlapping could be useful in terms of both matching customers with similar tastes and dealing with computational cost.
- Agrawal, A. (2018, June 13). Solving business usecases by recommender system using lightFM. Retrieved from https://towardsdatascience.com/solving-business-usecases-by-recommender-system-using-lightfm-4ba7b3ac8e62
- Kula, M. (2015). Metadata embeddings for user and item cold-start recommendations. arXiv preprint arXiv:1507.08439.
- Rendle, S., Freudenthaler, C., Gantner, Z., & Schmidt-Thieme, L. (2009, June). BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the twenty-fifth conference on uncertainty in artificial intelligence (pp. 452-461). AUAI Press.
- Rosenthal, E. (2016, November 7). Learning to rank Sketchfab models with LightFM. Retrieved from https://www.ethanrosenthal.com/2016/11/07/implicit-mf-part-2/
- Schröder, G., Thiele, M., & Lehner, W. (2011, October). Setting goals and choosing metrics for recommender system evaluations. In CEUR Workshop Proc (Vol. 811, pp. 78-85).
- Weston, J., Bengio, S., & Usunier, N. (2011, June). Wsabie: Scaling up to large vocabulary image annotation. In Twenty-Second International Joint Conference on Artificial Intelligence.