|By Yanmeng Song and Lang Qin|
Introduction
Either in the past or at present, when you try to find your way into the data science world, you might have this question in mind: what skills should I equip myself with and put on my resume to increase the chance of getting an interview and being hired. This question might keep popping up as new skills spring up quickly. After spending long hours searching for a job online, you close your laptop with a sigh. There are tons of information about how people define “data science” differently and it appears to be an ongoing discussion.
Based on LinkedIn’s third annual U.S. Emerging Jobs Report, the data scientist role is ranked third among the top-15 emerging jobs in the U.S. As the data science job market is exploding, a clear and in-depth understanding of what skills data scientists need becomes more important in landing such a position. This blog attempts to provide insights into this question in a “data science” way.
Problem Statement
According to the Business-Higher Education Forum (BHEF) report, by 2021, nearly 70% of executives in the United States will prefer job candidates with data skills. As stated in the Dice 2020 Tech Job Report, the demand for data science jobs will increase by 38% over the next 10 years. Catering to this growing need for data scientists in the job market, the past few years have seen a rapid increase in new degrees in data science offered by many top-notch universities. The demand for data scientists is booming and will only continue to increase in the future.
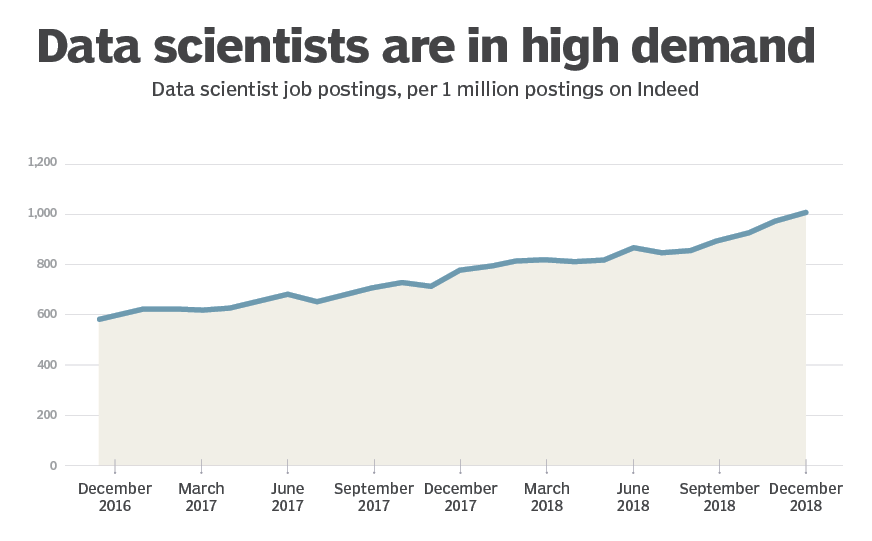
Though the data science job has become one of the most sought-after ones, there exists no standardized definition of this role and most people have an inadequate understanding of the knowledge and skills required by this subject. There are multiple other roles, such as data analysts, business analysts, data engineers, machine learning engineers, etc., usually thought of as similar, but could differ a lot in their functionalities. Radovilsky et al. (2018) pointed out that “data science emphasizes computer systems, algorithms, and computer programming skills, whereas business data analytics has a substantial focus on statistical and quantitative analysis of data, and decision-making support.” Furthermore, the required knowledge and skills are not static, but dynamic, as new and emerging skills spring up in this era of rapid technological development. Not to mention the required skill sets may vary among different business organizations for the exact same job title.
These situations pose great challenges for data science job seekers. What skills on earth do data scientists need to acquire? Just as resume parsers or resume extraction software applications are widely used by hiring organizations, the most direct approach to find the answer would be identifying skills from data science job postings, where qualifications and requirements for the role are usually clearly stated. However, there is usually a great deal of information contained in a single job posting. Manually analyzing them one by one would be very time-consuming and inefficient. This is exactly where natural language processing (NLP) can come into play and leads to the birth of this project.
Goal
In this project, we aim to investigate knowledge domains and skills that are most required for data scientists. In other words, we want to identify the most frequently used keywords for skills in corresponding job descriptions. We also aim to develop a pipeline that starts with raw job postings and produces analysis and visualization. In this way, new data could be fed in and it is possible to explore the dynamics of top required skills.
Bridging the gap between job postings and user profiles would tremendously benefit job seekers in the data science field. On the one hand, they would understand the job market better and know how to market themselves for better matching. On the other hand, it provides opportunities for them to learn or advance skills that they are not proficient in yet but are in high demand by hiring organizations. They could then decide to pursue a higher-level degree, or take an online course, or learn by practice, etc, to be well prepared for landing good jobs.
Methodology
We performed text analysis on associated job postings using four different methods: rule-based matching, word2vec, contextualized topic modeling, and named entity recognition (NER) with BERT. In the first method, the top skills for “data scientist” and “data analyst” were compared. A complete pipeline was built to create word clouds with top skills from job postings. The other three methods focused on “data scientist” and enabled us to experiment with the state-of-the-art models in NLP.
Data Collection
There is no such available dataset of data science job postings, so we collected them through web scraping from three popular job search engines — Indeed, Glassdoor, and LinkedIn. The associated job postings were searched by entering “data scientist” and “data analyst” keywords as job titles and “United States” as the location in the search bar.
For each job posting, five attributes were collected: job title, location, company, salary, and job description. The job description is the desired information while the remaining four attributes were excluded from the analysis for this project.
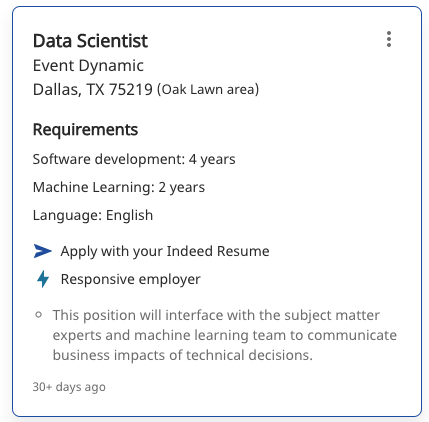
We faced several challenges in the process of web scraping. Firstly, website scripts and structures are updated frequently, which implies that the scraping code has to be constantly updated and maintained. The three job search engines we selected have different structures, so scripts need to be adjusted accordingly. Secondly, take Indeed as an instance (Figure 2), only the first bullet point or part of the detailed job description is displayed. The scraping scripts should include the click function to obtain the full context. Similarly, the automatic scraping process could be interrupted by a pop-up window asking for a job alert sign up, so the closing window function is also needed. Furthermore, based on our experiment, Glassdoor detects the web scraper as a bot after a few hundred requests, either time delay should be embedded between requests or wait for a while before it resumes.
With a single search, three job search engines restricted us to scrape only 1,000 job postings from each. After removing those without job descriptions and duplicates within a single dataset or across three datasets, we obtained 2,147 entries for “data scientist” and 2,078 entries for “data analyst”. Data cleaning was applied to those job descriptions, including lower case conversion, special characters, and extra white space removal, etc.
Analysis
This section gives a detailed description of the four methods. Both collected datasets were used in the rule-based matching method for the purpose of comparison. Only the dataset of “data scientist” was used in the other three methods to explore and identify the associated skills. In the future, the analysis can be replicated easily on “data analyst” by changing the input dataset to the pipeline.
I. Rule-Based Matching
Based on our job search experiences with “data scientist” and “data analyst”, we defined a dictionary containing commonly seen required skills into ten categories: statistics, machine learning, deep learning, R, Python, NLP, data engineering, business, software, and other. Some examples under the machine learning category are regression, predictive modeling, clustering, time series, PCA etc.
Using this predefined dictionary, we counted and ranked the occurrences of each skill in the two datasets. Then the corresponding word clouds were generated, with greater prominence given to skills that appear more frequently in the job description.
A complete pipeline was developed starting from web scraping to word cloud. As job postings are updated frequently, even within a minute, in the future, new data could be scraped and top skills could be identified from the word cloud through our pipeline. Additionally, the trend of top required skills could be captured by comparing data scrapped at different time points, in which we might see some particular skills gain more popularity in the industry as time goes by.
Note that the predefined dictionary is editable and expandable, to account for the rapidly changing data science field. Another feature of this method lies in its flexibility. We focused on the data science job market in this project, but it can actually be extended to other job positions/fields and tailored to specific locations you want. To achieve this, a new dictionary and new website URLs (for new job title and location) are needed.
II. Word2Vec
The Word2Vec algorithm (Mikolov et al., 2013) uses a neural network model to learn word vector representations that are good at predicting nearby words. It is considered one of the biggest breakthroughs in the field of NLP. As the name suggests, Word2Vec takes a corpus of text as input and produces a vector space, typically of several hundred dimensions, as output. Each unique word in the corpus is assigned to a vector in the space. Word vectors are positioned so that words that share common contexts in the corpus are located close to one another in the space (Innocent, 2019). Thus, word2vec could be evaluated by similarity measures, such as cosine similarity, indicating the level of semantic similarity between words.
There are two models for Word2Vec implementation — Continuous Bag-Of-Words (CBOW) and continuous Skip-gram (SG). The CBOW is learning to predict the word given the context, while the SG is designed to predict the context given the word.

In our case, Word2Vec could be leveraged to extract related skills for any set of provided keywords. Word-level tokenization and normalization (removing non-alphabetic chars and stop words etc.) were applied as the preprocessing step. We experimented with both models and conducted hyperparameter tuning, including the embedding size and the window size.
III. Contextualized topic modeling
Topic modeling is an unsupervised machine learning technique that is often used to extract words and phrases that are most representative of a set of documents. Different from traditional topic modeling techniques, such as Latent Dirichlet Allocation (Blei et al., 2003), contextualized topic modeling (Bianchi et al., 2020) uses a pre-trained representation of language together with a neural network structure, capable of generating more meaningful and coherent topics.
BERT (Bidirectional Encoder Representations from Transformers) was introduced in 2018 (Devlin et al., 2018). It is the latest language representation model and considered one of the most path-breaking developments in the field of NLP. It advances the state of the art for eleven NLP tasks. We used BERT as the pre-trained representation of language in this method.
The job descriptions are broken down into sentences and each sentence serves as a training sample. The model diagram is shown in Figure 4 below. Raw sentences went through a BERT embedding and were combined with the Bag-of-Words representation. The concatenated result went through a neural network framework, which approximates the Dirichlet prior to using the Gaussian distributions. The hidden layers were tuned to generate the topics. We chose the number of topics to be 20 with the assumption that job descriptions probably do not contain too many “topics.”

IV. Named entity recognition with BERT
Named entity recognition (NER) is an information extraction technique that identifies named entities in text documents and classifies them into predefined categories, such as person names, organizations, locations, and more. BERT, briefly mentioned in the previous method, involves two steps in its framework: pre-training and fine-tuning. The pre-trained BERT model can be fine-tuned with just one additional output layer to create cutting-edge models for a wide variety of NLP tasks.

Here we fine-tuned BERT for named entity recognition (Sterbak, 2018) to help identify the keywords for skills out of job descriptions. The skills correspond to entities that we want to recognize. If we highlight all the skills from the predefined dictionary in the sentence and feed them into the pre-trained BERT model, a more comprehensive set of skills could be obtained by analyzing the sentence structure. The input of the model is those sentences containing at least one skill from our dictionary. In other words, some sentences from the job description are not related to skills at all, such as company introduction and application instruction, and are thus excluded from the analysis. Each input sentence was first tokenized by the pre-trained tokenizer from BERT implementation. We limited the sequence length to be 50 tokens. Sequences less than 50 tokens were padded and sequences greater than 50 tokens were removed. There were only very few cases of the later one. In terms of the label, the tokens that match our dictionary were given labels of “1” (skill) and otherwise “0” (non-skill), but the tokens for padding purpose were labeled as “2” in order to differentiate from the rest. Similar to the masking in Keras, attention_mask is supported by the BERT model to enable neglect of the padded elements in the sequence. The output of the model is a sequence of three integer numbers (0 or 1 or 2) indicating the token belongs to a skill, a non-skill, or a padding token. An example from input to output is demonstrated in Figure 6.

Results
I. Rule-Based Matching
The output of the pipeline is two-word clouds as well as two full ranked lists of top skills with occurrence and percentage (i.e., count / total number of job postings) as shown in Figures 7, 8, and 9.
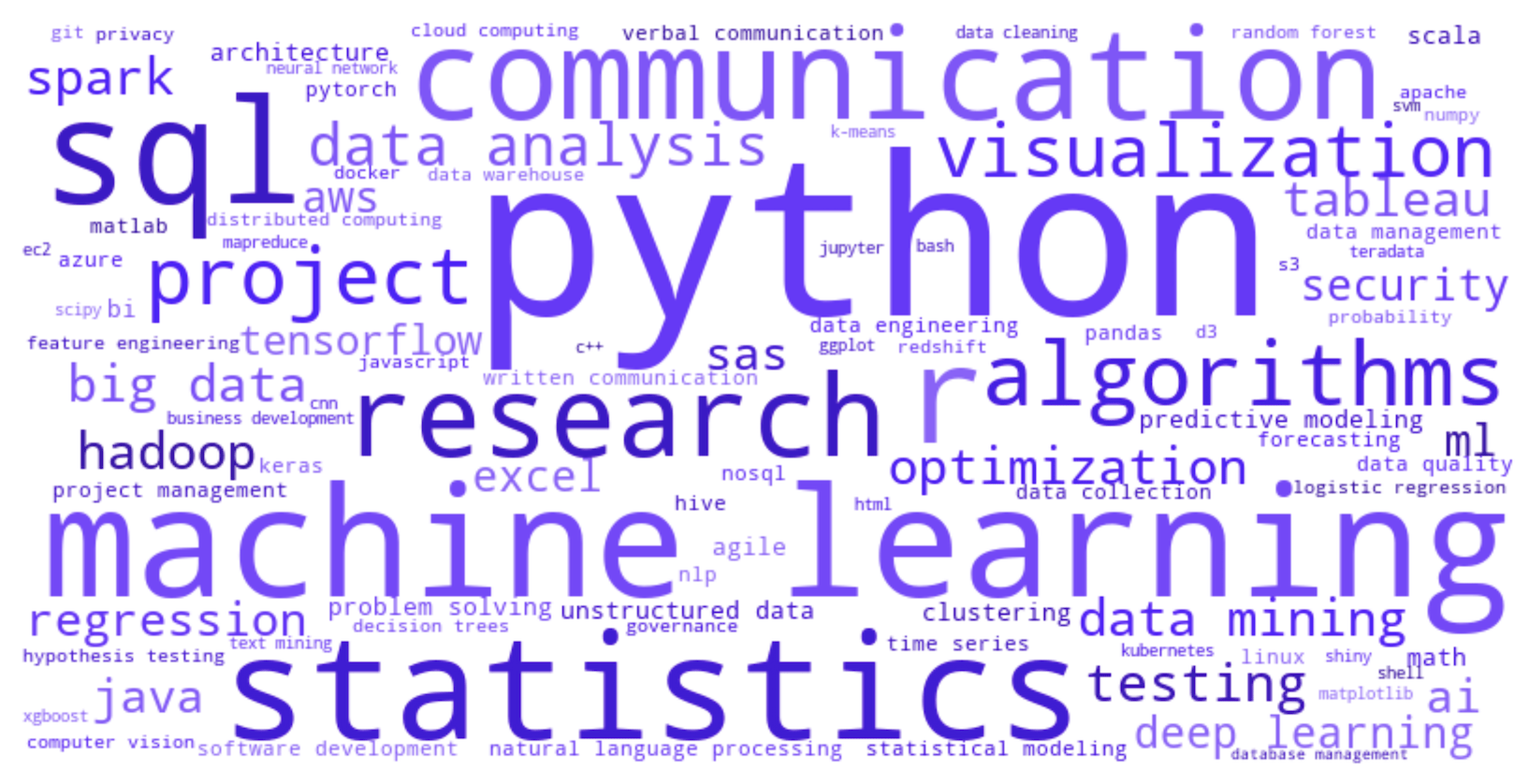

Figure 9 below illustrates the top ten identified skills, where the left one corresponds to data scientist and the right one corresponds to data analyst.

As we can see, Python, machine learning, and SQL are the top three for data scientists while SQL, communication, and Excel are the top three for data analysts. Among the two top ten lists, there are seven overlapping skills – Python, SQL, statistics, communication, research, project, visualization. We are surprised that R is not even in the top ten list for data analysts.
The above results are based on two datasets scraped in April 2020. We ran the whole pipeline again in September 2020, to test the functionality of the pipeline and investigate any potential changes of top skills. The results turn out to be very similar given the relatively short time interval.
II. Word2Vec
The results from the CBOW model and the SG model are similar. Different model parameters affect the result a bit but not that much. Overall the word embedding performed well in detecting other closely related skills. We picked “python” and “neural” as the candidate words and evaluated their closest neighbors in terms of cosine similarity. As we can see, the top 10 closest neighbors of “python” captured other programming languages, libraries, software applications, and frameworks. The top 10 closest neighbors of “neural” captured machine learning methods and probability related stuff in statistics.

Starting from the whole list of skills from our dictionary, a more comprehensive list of related skills could be identified, potentially including new skills not defined in the dictionary.
III. Contextualized topic modeling
Following the original paper of the combined topic model (Bianchi et al., 2020), the results were evaluated by the rank-biased overlap (RBO), which measures how diverse the topics generated by the model are. This measure allows disjointness between the topic lists and it is weighted by the word rankings in the topic lists. High value of RBO indicates that two ranked lists are very similar, whereas low value reveals they are dissimilar. We computed the rank-biased overlap diversity, which is interpreted as reciprocal of the standard RBO, on the top 10 keywords of the ranked lists. Correspondingly, high metric indicates the topic lists are dissimilar while low metric indicates the reverse. The result turned out to be 0.9937, demonstrating good topic diversity.
To identify the group that is more closely related to the skill sets, the bar chart was plotted showing the percentage of overlapped words out of the top 400 words in each topic with our predefined dictionary.

Topic 13 has a significantly higher overlap percentage than the other topics. It is most likely to be the topic describing the skill sets, and this is validated by reviewing the top words in that topic (see Figure 12 for details). For comparison, topic 20, with a much lower overlap percentage, has its top 50 words listed. We can safely conclude that it is describing the benefits, as words like “insurance”, “vision”, “dental”, “coverage”, and “holiday” suggest.
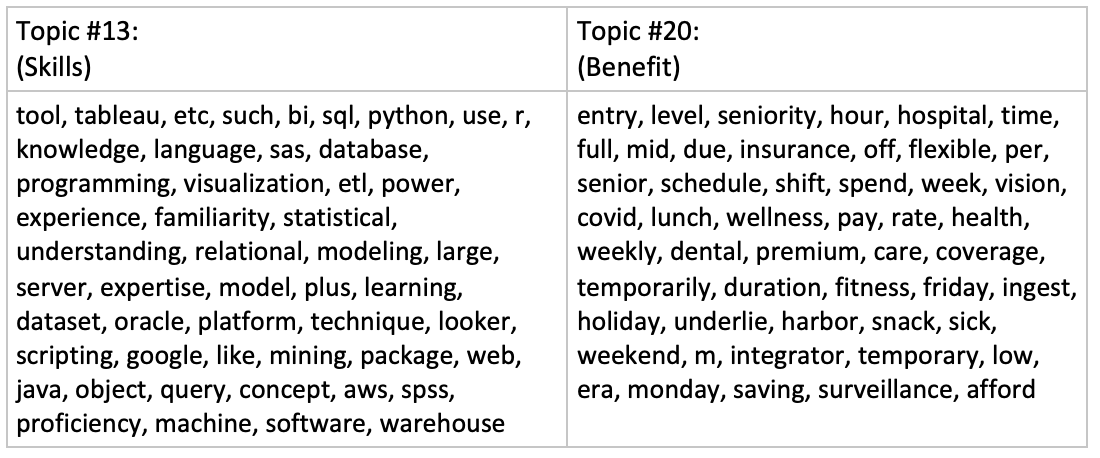
Topic 13 was selected for further analysis, and it would be called the skill topic for easy reference. We made a comparison between the words in the skill topic and those in the predefined dictionary. The objective is two-fold: (i) it provides a qualitative evaluation of the combined topic model, especially for the skill topic; (ii) it provides an insight into the potential of the skill topic in identifying new skills not defined in the dictionary. Word clouds in Figure 14 present the results in a visual way, and the annotations are explained through the Venn diagram in Figure 13.

Uncaptured words are those defined in the dictionary but not captured by the skill topic. Examples like “communication”, “management”, “network” are more general skills and might be captured in another topic of the model. They could appear in another part of the job description and thus not be representative of the sentence describing specific skills. However, examples like “statistics”, “gbm”, “ai” might indicate the flaw of the model since they are expected to be captured skills. Overlapped words are those that appear in both the dictionary and the skill topic. Undefined words are those not defined in the dictionary but appear in the skill topic. This category is interesting and deserves attention. Some words are descriptions for the level of expertise, such as “familiarity”, “experience”, “understanding”. Besides, words like “postgre”, “server”, “programming”, “oracle” inform that the dictionary is not robust enough. More importantly, this category is able to identify new and emerging skills we are not aware of yet, rather than being limited to a set of known skills. This is unachievable by the rule-based matching method without the input of domain knowledge from experts, but of great importance to allow for rapid change in the data science field.

A further quantitative evaluation was conducted on the discrepancy between the dictionary and the skill topic. Take the predefined dictionary as ground truth, we define precision as “percentage of dictionary words in the top K words of the skill topic”, recall as “in the top K words of the skill topic, the proportion of overlapped words with dictionary to the total number of words in dictionary”. For instance, among the top 50 words in the skill topic, 21 of them (42%) appear in the dictionary, so the precision is 0.42; these 21 words account for 9.5% of all words in the dictionary, so the recall is 0.095. By varying K from 50 to 400, a precision-recall curve is plotted. The steeper slope at the beginning indicates the proportion of overlapped words decreases as K increases. That is to say, the overlapping concentrates in the top words of the skill topic. The slope flattens after 150 words, so 150 is a proper K to capture enough skills while ignoring irrelevant words.

IV. Named entity recognition with BERT
We randomly split the dataset into the training and validation set with a ratio of 9:1. The training data was fed into the BERT model for 3 epochs of fine-tuning. Cross entropy was used as the loss function and AdamW was used as the optimizer. The training process took around 7 hours using our own computer. Training loss and validation loss are plotted below. After 3 epochs, the training loss is 0.0023 and the validation loss is 0.0073.

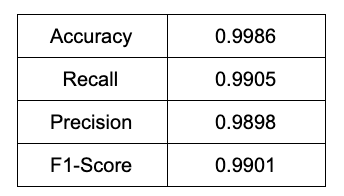
Performance metrics for the validation set are summarized in Table 1. All four metrics have high values. However, such a high value of predictive accuracy actually means a high degree of coincidence with the rule-based matching method. We wish the model to have a high recall but relatively low precision. In this way, it is extensible and probably helps us identify new skills not included in the dictionary, namely the false-positive part.
Even with high precision, this method still finds some extra keywords, as shown in the figure below, such as “randomized grid search”, “factorization”, “statistical testing”, “Bayesian modeling” etc.

Summary
We applied four different approaches of skills extraction from data science job postings. Data science job seekers could use identified knowledge domains and skills from these four approaches as a guide in their job search, not only to understand the job market and better market themselves but also to improve and/or learn new skills if necessary.
From the methodological point of view, in the first method, in addition to identifying top required skills, a complete pipeline was built to address the variability property of skills and enable to explore the trend of top required skills in the data science field. The other three methods are more like applications of traditional as well as superlative models in NLP.
- The rule-based matching method requires the construction of a dictionary in advance. The identified top skills would be limited to the predefined set of skills. This limitation could be alleviated thanks to our pipeline. As long as the dictionary is updated, new word clouds would be generated quickly, though updating requires knowledge from domain experts and it is prone to subjectiveness. The good thing is that no training is needed and new data could be easily fed in by changing the website URL in web scraping script. It is also possible to learn the trend of top required skills in the data science field.
- The word2vec method is able to find new skills. Using the dictionary as a base, a much larger list of skills could be identified. The key in this method is word embedding.
- The contextualized topic modeling method is an unsupervised machine learning technique and is able to find new skills too. Our current evaluation is dependent on the dictionary. It is inevitable that some skills are distributed in other topics besides the most concentrated one, so the choice of topic numbers is important.
- The named entity recognition with BERT method belongs to the supervised machine learning category and is able to identify new skills. The current labeling is imperfect due to its complete dependence on the dictionary. If equipped with better labeling, this method should be more powerful. Another unique advantage of this method is that it can capture phrases with two or more word grams.

Limitations and Future Work
Due to the limitations on the maximum number of job postings scraped with a single search, our data size is very small. Future work should consider combining data from more job boards or from several periodic scraping. A larger data size would be beneficial to all four methods and improve the results.
More text preprocessing and cleanup work could be done in the future to reduce noise. Stemming and word bigram might also be helpful.
The dictionary is defined by ourselves and definitely not robust enough. The ability to identify new skills of other methods would be augmented using a more comprehensive dictionary.
In the NER with BERT method, it might be worth trying an iterative approach. That is to say, the first iteration does labeling by matching against the dictionary, then the identified new skills together with the dictionary function as new labeling for the next iteration. This is sort of semi-supervised and the skill set would gradually enlarge. Another alternative would be manual labeling, though very laborious. Note that BERT takes a while to train, so future work should consider the training on GPU.
We experimented with the long short-term memory (LSTM) architecture but it did not produce good results because of the small data size and skill versus non-skill imbalance. Deep learning methods are worth trying if these issues could be addressed.
References
Bianchi, F., Terragni, S., & Hovy, D. (2020). Contextualized Topic Models, GitHub repository, https://github.com/MilaNLProc/contextualized-topic-models
Bianchi, F., Terragni, S., & Hovy, D. (2020). Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv preprint arXiv:2004.03974.
BHEF (2017, April). Investing in America’s data science and analytics talent. Retrieved from https://www.bhef.com/sites/default/files/bhef_2017_investing_in_dsa.pdf
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Dice (2020). The Dice 2020 Tech Job Report. Retrieved from https://techhub.dice.com/Dice-2020-Tech-Job-Report.html
Innocent, A. (2019, September 29). Word Embeddings: Beginner’s In-depth Introduction. Retrieved from https://medium.com/@melchhepta/word-embeddings-beginners-in-depth-introduction-d8aedd84ed35
LinkedIn (2020). 2020 Emerging Jobs Report. Retrieved from https://business.linkedin.com/content/dam/me/business/en-us/talent-solutions/emerging-jobs-report/Emerging_Jobs_Report_U.S._FINAL.pdf
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
Radovilsky, Z., Hegde, V., Acharya, A., & Uma, U. (2018). Skills requirements of business data analytics and data science jobs: A comparative analysis. Journal of Supply Chain and Operations Management, 16(1), 82.
Sterbak, T. (2018, December 10). Named entity recognition with Bert. Retrieved from https://www.depends-on-the-definition.com/named-entity-recognition-with-bert/
Relevant code is available here: https://github.com/yanmsong/Skills-Extraction-from-Data-Science-Job-Postings
Acknowledgments
We would like to express our very great appreciation to Dr. Borchuluun Yadamsuren for research guidance, feedback, and copyediting. Special thanks also to Dr. Emilia Apostolova for professional guidance and constructive suggestions.