1.Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution



Video super-resolution (VSR) has become one of the most critical problems in video processing. In the deep learning literature, recent works have shown the benefits of using adversarial-based and perceptual losses to improve the performance on various image restoration tasks; however, these have yet to be applied for video super-resolution. In this paper, we propose a generative adversarial network (GAN)-based formulation for VSR. We introduce a new generator network optimized for the VSR problem, named VSRResNet, along with new discriminator architecture to properly guide VSRResNet during the GAN training. We further enhance our VSR GAN formulation with two regularizers, a distance loss in feature-space and pixel-space, to obtain our final VSRResFeatGAN model. We show that pre-training our generator with the mean-squared-error loss only quantitatively surpasses the current state-of-the-art VSR models. Finally, we employ the PercepDist metric to compare the state-of-the-art VSR models. We show that this metric more accurately evaluates the perceptual quality of SR solutions obtained from neural networks, compared with the commonly used PSNR/SSIM metrics. Finally, we show that our proposed model, the VSRResFeatGAN model, outperforms the current state-of-the-art SR models, both quantitatively and qualitatively.
More details could be found here
2.Spatially Adaptive Losses for Video Super-Resolution with GANs

Deep Learning techniques and more specifically Generative Adversarial Networks (GANs) have recently been used for solving the video super-resolution (VSR) problem. In some of the published works, feature-based perceptual losses have also been used, resulting in promising results. While there has been work in the literature incorporating temporal information into the loss function, studies which makes use of the spatial activity to improve GAN models are still lacking. Towards this end, this paper aims to train a GAN guided by a spatially adaptive loss function. Experimental results demonstrate that the learned model achieves improved results with sharper images, fewer artifacts and less noise.
More details could be found here
3.Semantic Prior Based Generative Adversarial Network for Video Super-Resolution
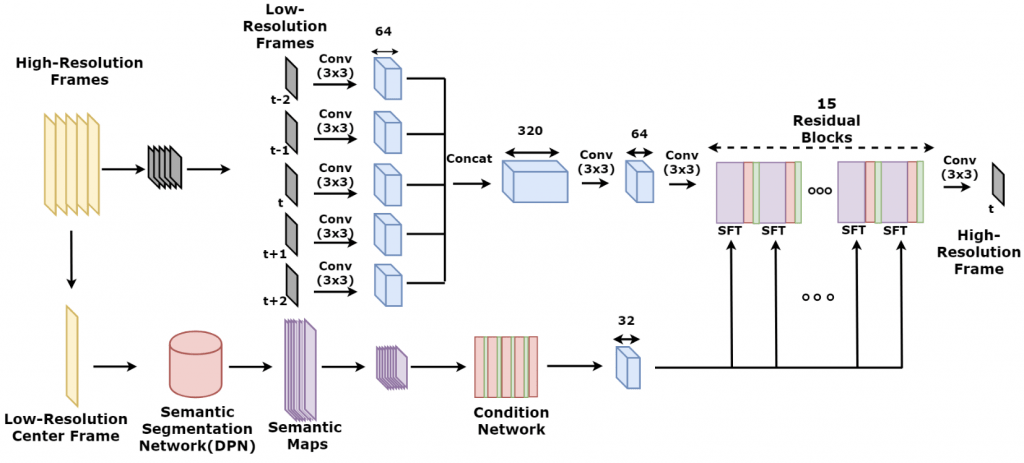
Semantic information is widely used in the deep learning literature to improve the performance of visual media processing. In this work, we propose a semantic prior based Generative Adversarial Network (GAN) model for video super-resolution. The model fully utilizes various texture styles from different semantic categories of video-frame patches, contributing to more accurate and efficient learning for the generator. Based on the GAN framework, we introduce the semantic prior by making use of the spatial feature transform during the learning process of the generator. The patch-wise semantic prior is extracted on the whole video frame by a semantic segmentation network. A hybrid loss function is designed to guide the learning performance. Experimental results show that our proposed model is advantageous in sharpening video frames, reducing noise and artifacts, and recovering realistic textures.
More details could be found here
4.Semantic Prior Based Generative Adversarial Network for Video Super-Resolution

Generative Adversarial Networks (GANs) have been used for solving the video super-resolution problem. So far, video super-resolution GAN-based methods use the traditional GAN framework which consists of a single generator and a single discriminator that are trained against each other. In this work we propose a new framework which incorporates two collaborative discriminators whose aim is to jointly improve the quality of the reconstructed video sequence. While one dis- criminator concentrates on general properties of the images, the second one specializes on obtaining realistically reconstructed features, such as, edges. Experiments results demonstrate that the learned model outperforms current state of the art models and obtains super-resolved frames, with fine details, sharp edges, and fewer artifacts.
More details could be found here
4.A Single Video Super-Resolution GAN for Multiple Downsampling Operators based on Pseudo-Inverse Image Formation Models


The popularity of high and ultra-high definition displays has led to the need for methods to improve the quality of videos already obtained at much lower resolutions. Current Video Super-Resolution methods are not robust to mismatch between training and testing degradation models since they are trained against a single degradation model (usually bicubic downsampling). This causes their performance to deteriorate in real-life applications.
At the same time, the use of only the Mean Squared Error during learning causes the resulting images to be too smooth. Thought the use of perceptual losses (adversarial and feature losses) has been proposed to increase the perceptual quality and sharpness of the produced frames, these losses also introduced high frequency artifacts that are very difficult to remove.
In this work we propose a new Convolutional Neural Network for video super resolution which is robust to multiple degradation models. During training, which is performed on a large dataset of scenes with slow and fast motions, it uses the pseudo-inverse image formation model as part of the network architecture in conjunction with perceptual losses, in addition to a smoothness constraint that eliminates the artifacts originating from these perceptual losses. The experimental validation shows that our approach outperforms current state-of-the-art methods and is robust to multiple degradations.
More details can be found here.
Project Sponsor
