| By Logan Wilson |
Where do you find new music?
If you’re listening to post-grunge on your Sony Walkman, congratulations, you’re still in 1999! You discover new music primarily through the radio, at the mercy of disk jockeys playing actual disks, or by wandering aimlessly around record stores, hoping to be inspired by some bangin’ album artwork.

However, if you’ve listened to music at any point since then, you probably discover new music online – Pandora, YouTube and Spotify seem to know your musical tastes better than DJ Dave on 92.1 FM ever could.
How do these digital DJs know what you like? Modern music recommendation systems can generally be classified as content-based systems, collaborative filtering systems, or a hybrid of the two. Content-based systems make recommendations based on attributes of the sound of the music – is the song happy? Does it have a strong beat? On the contrary, collaborative filtering systems are based on user behavior – you and Bill both liked Red Hot Chili Peppers, and Bill also liked blink-182, so you’ll probably like blink-182 as well. Companies like Spotify and Pandora generally utilize a combination of the two with a strong focus on collaborative filtering – individual musical tastes are fickle, but given a large enough sample size, humans are pretty predictable.
I wanted to see if I could build my own music recommendation system similar to Spotify’s “Discover Weekly” playlists by applying some basic machine learning techniques – namely, the random forest algorithm. Lacking Spotify’s massive ocean of user data, DJ Random Forest recommends music by implementing a content-based algorithm in which recommendations are based entirely on personal ratings, using only genre and audio features. Audio features encompass 10 qualitative attributes (such as danceability, energy, acousticness, etc.) evaluated quantitatively by the music intelligence platform Echo Nest, acquired by Spotify in 2014. These audio features, along with other identifying track information such as track name, artist, album, and genre were obtained via the Spotify Web API.
In order to build a comprehensive data set, I wanted music that would appeal to most modern tastes, but with enough relatively unknown artists or songs that ratings wouldn’t be muddied by familiar tunes. If the user’s primary goal is to to find new songs or artists to enjoy, the model should be trained on new songs based on whether the user likes its sound, rather than whether the user has a preconceived opinion of the artist. In order to generate such a dataset, I extracted the names of 427 unique artists from the Billboard Year-End Hot 100 charts for 2005 through 2015 scraped from Wikipedia (https://github.com/walkerkq/musiclyrics). After querying each artist’s name to obtain their Spotify-assigned Artist ID, I used Spotify’s “related artists” API method to get 20 related artists for each artist. I repeated this to get 20 related artists for each of these artists, until I had a list of over 8500 unique artists. I then used Spotify’s “top tracks” and “audio features” API methods to get the top 10 tracks and their associated audio features for each of these artists. Every artist also has an associated list of sub-genres, which I parsed into a single parent genre classification. The end result of this was a single data frame containing exhaustive data and metadata for 80,600 tracks on which a machine learning model could be trained.
I wanted the process of getting song recommendations from DJ Random Forest to be fun and easy. The console-based user experience is fairly straightforward and guided by helpful prompts along the way. Initially, the user is prompted to listen to 30-second previews of several songs and rate them on a scale of 1-10, with a minimum of 10 recommended (obviously, the more samples the better). The ratings are converted into binomial responses, with ratings greater than 5 classified as “like”, and ratings less than or equal to 5 classified as “dislike.” Weights are assigned to each response depending on the magnitude of the rating (a rating of 1 or 10 are weighted higher than a rating of 2 or 9, and so on).
A random forest classification model is then trained on the rated songs. Though scikit-learn is generally the library of choice for machine learning in Python, I implemented the H2O machine learning platform for its advanced support for categorical data (scikit-learn’s random forest classifier can only make numerical splits on variables for its decision trees and would require one-hot encoding of the categorical data in the genre variable, but H2O can perform categorical splits within its decision trees).
For each of the remaining songs in the dataset, the model predicts the probability that a song will receive a positive response (i.e. rating > 5). The 10 songs with the highest probabilities are shown to the user, who can choose to either see the next top 10 songs or rate more songs. The user can choose to either rate their top songs or new, random songs. After this second round of training, the user is presented with the top 10 songs recommended by the improved model (trained on 20 songs rather than 10, for instance). This continues until the user is satisfied and quits the program.
Choosing a metric to evaluate our model poses an interesting problem – since we are not interested in observing classifications for the entire test set of 80,000 songs (most users will only view the top 10 songs in the test set), high accuracy is unnecessary. Any songs close to the threshold between “like” and “dislike” will likely never be seen, so their classification is inconsequential. We must also account for users who might like or dislike a large proportion of the songs in the training data – for example, if the user likes 9 out of 10 songs, accuracy will be high if the model classifies every song as “like.” AUC, which measures the likelihood that a “like” song will be ranked higher than a “dislike” song, is therefore the preferred metric for this model.
A model built on a small training dataset like ours can certainly be prone to overfitting, though the random forest algorithm should alleviate this to a certain extent through the process of bagging on both sample and predictor selection. To further mitigate this, we can tune parameters min_rows and ntrees, where min_rows specifies the minimum number of observations for a leaf in order to split and ntrees specifies the number of trees to build. Ideally we would also tune the maximum depth to which a tree could be built, but during testing we found that setting a low maximum depth would result in too many short trees with few leaf nodes due to the small training dataset. This would cause “like” probabilities to be bucketed into several discrete values and prevent a definitive ranking from which we would determine the top 10 songs. By allowing trees to grow to their full extent (i.e. no maximum depth), we can obtain granularized probabilities for ranking without sacrificing significant predictive power.
We can select the right combination of min_rows and ntrees through cross-validation, employing the “leave-one-out” method and averaging AUC over all of the resultant models for a given combination of parameters. For the purpose of tuning, I had my roommate complete the initial stage of the program, rating 10 random songs to create a training dataset. I used this training data to build 90 different models using different combinations of min_rows and ntrees, then grouped by min_rows and ntrees and averaged AUC values.
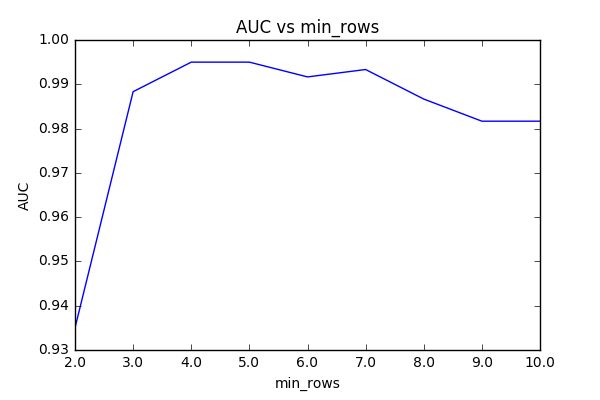
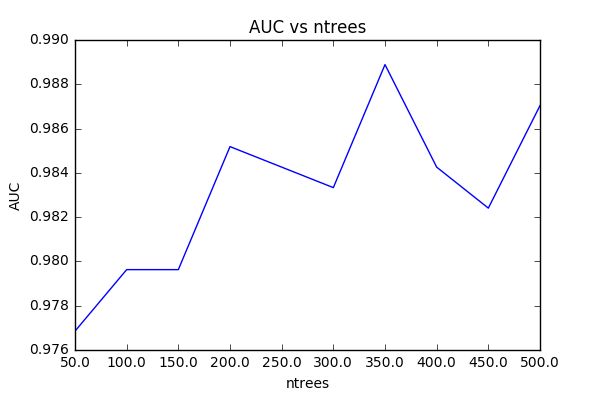
In Figure 2, we see that AUC stays fairly consistent for min_rows >2. In Figure 3, we observe that AUC rises fairly linearly with ntrees (notwithstanding a few spikes), which follows from our intuition that more trees should provide better performance (but worse speed). We will select min_rows=3 and ntrees=350 for our model. One should note that the AUC for all of these models is very close to 1 within a very small range, indicating strong predictive power regardless of tuning. That said, all of these models were built from the same individualized dataset. Ideal parameters will likely vary depending on the variety of songs sampled for training and the rating behavior of the user.
Once we are satisfied with the tuning of the model, we can begin actually making predictions. After setting these new parameters, I had my roommate complete 4 rounds of the second stage of the program, rating the top 10 songs recommended by each iteration of the model. We can observe how the model improves over each iteration through a few different metrics.

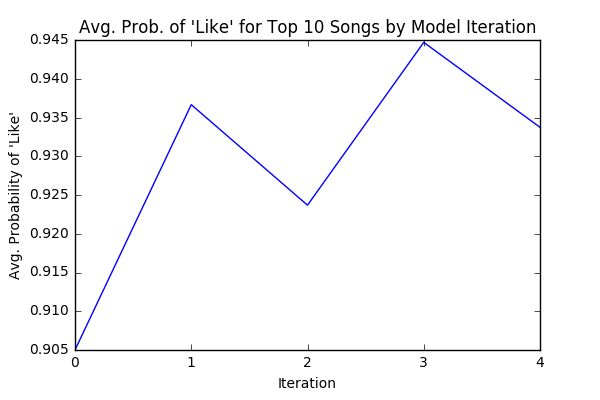

First, we can measure AUC for each iteration of the model, calculated from the training data on which the model was fitted. We see in Figure 4 that AUC drops to a fairly stable range after the initial training model (iteration 0) – this is likely due to some overfitting in the initial iteration when the sample size is small, which corrects itself when sample size is sufficiently large. We can also average the probability of a “like” response for the top 10 recommended songs for each iteration. The plot in Figure 5 follows a roughly linear trend, indicating that the model is growing more certain about its predictions as it improves. Of course, the metric that ultimately matters is whether the user likes the recommendations. Averaging ratings for each set of recommended songs, the plot in Figure 6 indicates that on average, the user’s ratings increase after each iteration of the model.
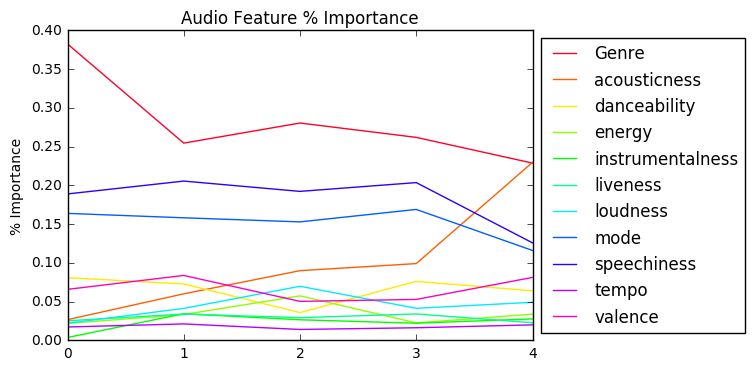
We can also utilize the model’s ranking of variable importance (Figure 7) to draw some conclusions about the user’s musical tastes. This user ranks music primarily by genre, but also considers speechiness (a measure of the presence of spoken words on a track), mode (either major or minor scale), and acousticness. A full description of all audio features is available in the documentation for the Spotify Web API.
Of course, all of these results are highly individualized to my roommate’s preferences, so we can’t yet draw definitive conclusions about the effectiveness of the model. The next stage for DJ Random Forest would be beta-testing – allowing others to test the program and recording their results. With more data, we could not only study and improve the performance of the algorithm via further tuning, but also begin modelling musical tastes over different demographics. What makes a popular song popular? Do millennials prioritize tempo and loudness while single moms prioritize danceability? DJ Random Forest may one day find out.
DJ Random Forest is available for download via Github: https://github.com/lwilson18/DJ-RandomForest.