
Bingda Huang
Economics is a science that can help humans solve the problem of rational allocation and full utilization of resources. At a micro level, it can help us better understand our world and use economic thinking to view and analyze some people and things rationally. Even if we can’t know that we are making the right choices, it can help us avoid falling into some traps in life. This short article will help you understand the basic concepts of consumer surplus and producer surplus in economics and how they relate to calculus.
Before we get into consumer and producer surplus, let’s take a quick look at demand and supply curves. Basically, the quantity of a certain item produced and sold can be described by the supply and demand curves of the item. The supply curve shows what quantity, 


Supply and Demand Curves
The logic of the model of demand and supply is simple. By putting the two curves together, we should be able to find a price at which the quantity buyers are willing and able to purchase equals the quantity sellers will offer for sale (This price is called the equilibrium price). At equilibrium, a quantity 



- Consumer surplus measures the consumers’ gain from trade. It is the total amount gained by consumers by buying the item at the current price rather than at the price they would have been willing to pay.
- Producer surplus measures the suppliers’ gain from trade. It is the total amount gained by producers by selling at the current price, rather than at the price they would have been willing to accept.
In brief, Both consumers and producers are richer for having traded. The consumer and producer surplus measures how much richer they are. See graph:

Consumer and Producer Surplus
In reality, sometimes, markets can produce changes. In a free market, the price of a product usually moves toward the equilibrium price, but the presence of external forces can make the price artificially high or artificially low. For example, rent control keeps prices below market value, while cartel pricing or minimum wage laws keep prices above market value. What happens to consumer and producer surplus at disequilibrium prices? Here is an example to help us find out:
The dairy industry has cartel pricing: the government has set milk prices artificially high. What effect does raising the price to 

Figure (1)
Figure (1) above gives a graph of possible supply and demand curves for the milk industry. Assume that the price is fixed at

Figure (2)
For producer surplus: at price 

Figure (3)
In summary, for the change in overall returns: the shaded area in Figure (4) below indicates the total gains from trade at a price

Figure (4)

Figure (5)
Since we know all about the concepts of consumer and producer surplus, it is time to introduce how they relate to the fields of calculus and mathematics. Under the field of calculus, we can use the knowledge of relevant integrals to help us quickly find the consumer or producer surplus.
Now assume that all consumers buy the item at the highest price they are willing to pay. And divide the interval from 0 to 

Figure (6)
As Figure (6) shows, a certain number of 

![]()
Expressed in integral form:
If the equation of the demand curve is ")
![]()
We know that consumer surplus represents the extra money that ends up in the consumer’s pocket, and it is the area between the demand curve and the horizontal line
 dq - p^*q^*")
Similarly, the producer surplus represents the amount of extra money that ends up in the producer’s pocket, and it is the area between the supply curve and the horizontal line at ")
 dq")
In summary, we can easily find the consumer and producer surplus using the two integral formulas above.
As stated at the beginning of this blog, economics can help you analyze things rationally, and I hope these consumer and producer surplus contents can help you solve economics or similar problems in the future.
Sources
- Hughes-Hallett, D., Gleason, A. M., Lock, P. F., Flath, D. E., et al. Applied Calculus. 5th ed., Wiley, 2013.
- “Principles of Economics”. the University of Minnesota Libraries, 2011. 3.3 Demand, Supply, and Equilibrium – Principles of Economics (umn.edu)
- “Business Calculus with Excel”. Mike May, S.J. & Anneke Bart, May 15, 2023. 7.8: Economics Applications of the Integral – Mathematics LibreTexts


} \approx 1250-400 = 850~\text{m}^3/\text{s}")
} \approx 15~\text{days}")
 \times (15~\text{days})")
 \times (1,296,000~\text{s}) = 1.1016 \times 10^9~\text{m}^3")

} \approx 3500-250 = 3250~\text{m}^3/\text{s}")
} \approx 4~\text{months} = 122~\text{days}")
 \times (122~\text{days})")
 )
)  \times (1.054 \times 10^7~\text{s}) = 1.7128 \times 10^{10}~\text{m}^3")
")

=x")
=0")
 ,
,) dx")
 The portion of the graph under the Lorenz curve is called the fairest distribution. Smaller areas mean a fairer distribution of resources across the population. For example, here is a graphical representation of Gini’s Index of Inequality.
The portion of the graph under the Lorenz curve is called the fairest distribution. Smaller areas mean a fairer distribution of resources across the population. For example, here is a graphical representation of Gini’s Index of Inequality. 

")
 Congratulations! Now you have the knowledge to understand some very important questions surrounding the distribution of resources. Understanding this concept will allow you to compare countries and understand which populations are most affected by unequal distribution of resources. Unequal distribution of natural resources is one of the biggest perpetrators in economic and geopolitical power relations that can influence major conflict. In the long run, this can help raise awareness for populations and countries struggling with inequality, and help those struggling countries achieve perfect equality of resource distribution.
Congratulations! Now you have the knowledge to understand some very important questions surrounding the distribution of resources. Understanding this concept will allow you to compare countries and understand which populations are most affected by unequal distribution of resources. Unequal distribution of natural resources is one of the biggest perpetrators in economic and geopolitical power relations that can influence major conflict. In the long run, this can help raise awareness for populations and countries struggling with inequality, and help those struggling countries achieve perfect equality of resource distribution. 

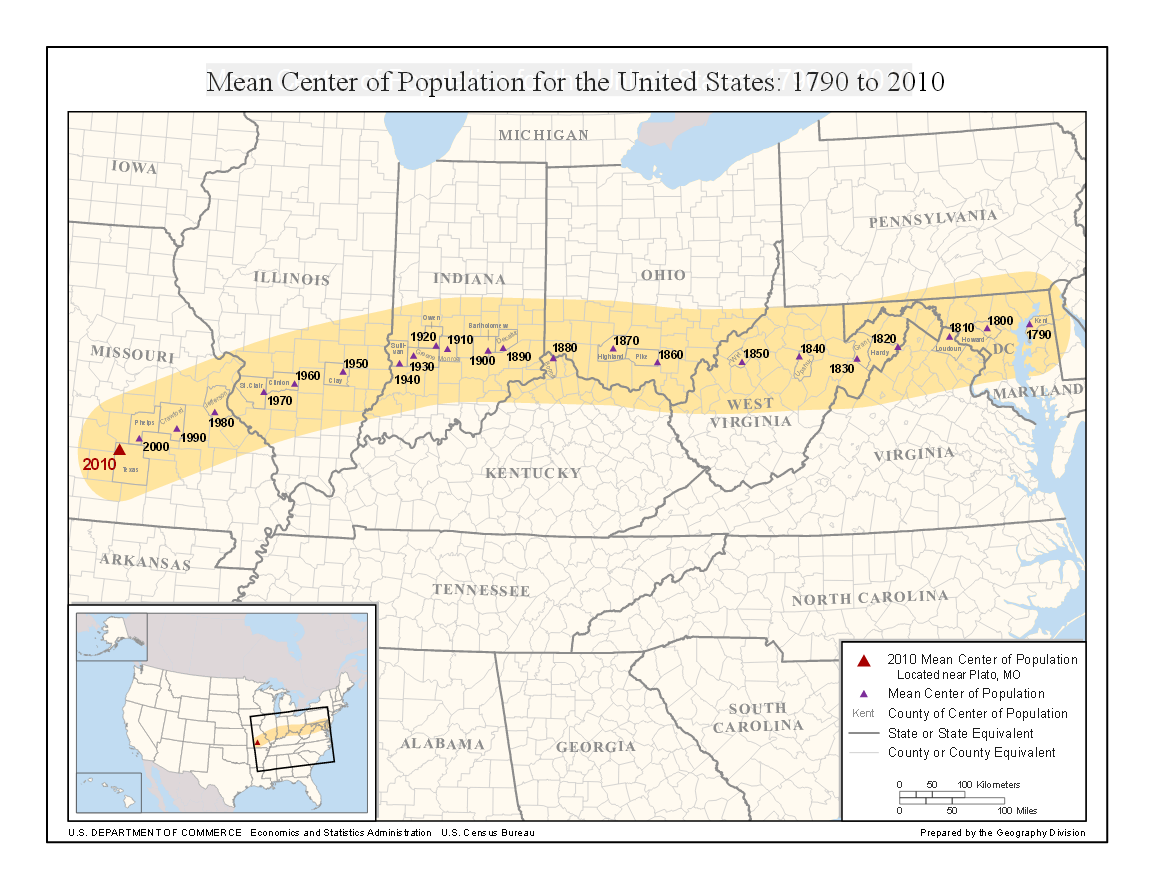
 represents the number of years since 2000. Considering that the population centre moved 50 miles west every ten years, we can conclude that it moves at a rate of 5 miles per year. Thus, the approximate position of the population centre, measured westward from Edgar Springs along the line through Baltimore, can be given by the equation:
represents the number of years since 2000. Considering that the population centre moved 50 miles west every ten years, we can conclude that it moves at a rate of 5 miles per year. Thus, the approximate position of the population centre, measured westward from Edgar Springs along the line through Baltimore, can be given by the equation:  = 5t")

 .
.
 = 303+1.3t") ,
,  = 304e^{0.0038t}") ,
,  = 0.0135t^2+0.5133t+310.5")
") , is a linear function model, which is the simplest and therefore best used for quicker approximations. This linear model shows us right away that there is a positive continuous growth trend in the data with respect to time, with a positive slope of 1.3 ppm/year; meaning that if the data were to fit a simple linear model starting with 303 ppm of CO₂ in 1950, the concentration sh
, is a linear function model, which is the simplest and therefore best used for quicker approximations. This linear model shows us right away that there is a positive continuous growth trend in the data with respect to time, with a positive slope of 1.3 ppm/year; meaning that if the data were to fit a simple linear model starting with 303 ppm of CO₂ in 1950, the concentration sh .
.") , is an exponential function model. This function is able to give a more detailed description of the variation in carbon dioxide concentrations since 1950, because as an exponential growth curve, it now tells us that the slope of the function becomes steeper as time moves forward. In other words: the rate of change that determines the amount of carbon dioxide concentration in a specific year gets larger as time goes on. This is a representation of how a portion of carbon dioxide becomes trapped in the atmosphere each year, compounding onto the portion that was already trapped. So, the rate of change is not constant. Therefore, in contrast to the linear model, if we wanted to predict what the rate of change of CO₂ would be in a specific year like 2010, we would need to find the slope of the line tangent to the curve at that specific data point in the year 2010. This means finding the derivative of the function, and then plugging in 60 years for
, is an exponential function model. This function is able to give a more detailed description of the variation in carbon dioxide concentrations since 1950, because as an exponential growth curve, it now tells us that the slope of the function becomes steeper as time moves forward. In other words: the rate of change that determines the amount of carbon dioxide concentration in a specific year gets larger as time goes on. This is a representation of how a portion of carbon dioxide becomes trapped in the atmosphere each year, compounding onto the portion that was already trapped. So, the rate of change is not constant. Therefore, in contrast to the linear model, if we wanted to predict what the rate of change of CO₂ would be in a specific year like 2010, we would need to find the slope of the line tangent to the curve at that specific data point in the year 2010. This means finding the derivative of the function, and then plugging in 60 years for  ). To find the derivative, we use the exponential rule, which is a variation of the chain rule: the full function
). To find the derivative, we use the exponential rule, which is a variation of the chain rule: the full function  . Plugging 60 years for
. Plugging 60 years for ") , is a quadratic polynomial function model. This model insinuates that the graph is shaped like a parabola; however, we are only looking at one side of the parabola in terms of growth rate of CO₂ levels in relation to time, which can only be where
, is a quadratic polynomial function model. This model insinuates that the graph is shaped like a parabola; however, we are only looking at one side of the parabola in terms of growth rate of CO₂ levels in relation to time, which can only be where  . Therefore, this model shows that when
. Therefore, this model shows that when t+ 0.5133") . Plugging in 60 for
. Plugging in 60 for 

=x^{a}") (
( (
(") (
( (2 \times 3 = 6) or
(2 \times 3 = 6) or  (2 \cdot 3 = 6)
(2 \cdot 3 = 6) (\frac{1}{x}) or
(\frac{1}{x}) or  (\dfrac{1}{x})
(\dfrac{1}{x}) (e^{-2x}, but not e^-2x, because the latter will produce
(e^{-2x}, but not e^-2x, because the latter will produce  )
) (P_{0}) or
(P_{0}) or  (a_{10}, but not a_10, because the latter will produce
(a_{10}, but not a_10, because the latter will produce  )
) -th roots.
-th roots. or
or ![\sqrt[3]{10}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B3%5D%7B10%7D&bg=ffffff&fg=000000&s=0 "\sqrt[3]{10}") (\sqrt{10} or \sqrt[3]{10})
(\sqrt{10} or \sqrt[3]{10})") ,
, ") , or
, or ") (\sin(x), \cos(x), or \ln(x))
(\sin(x), \cos(x), or \ln(x)) and
and  , and use \int for an indefinite integral
, and use \int for an indefinite integral dx") or
or  dx") (\int_{a}^{b} f(x) dx or \int f(x) dx)
(\int_{a}^{b} f(x) dx or \int f(x) dx)![\dfrac{d}{dx}[\sqrt{x^2-3x+3}] = \dfrac{2x-3}{2\sqrt{x^2-3x+3}}](https://s0.wp.com/latex.php?latex=%5Cdfrac%7Bd%7D%7Bdx%7D%5B%5Csqrt%7Bx%5E2-3x%2B3%7D%5D+%3D+%5Cdfrac%7B2x-3%7D%7B2%5Csqrt%7Bx%5E2-3x%2B3%7D%7D&bg=ffffff&fg=000000&s=0 "\dfrac{d}{dx}[\sqrt{x^2-3x+3}] = \dfrac{2x-3}{2\sqrt{x^2-3x+3}}")
 .
.