| By Kehan (Eric) Pan |
Introduction
Natural Language Processing (NLP) is rarely used in recommender systems, let alone in movie recommendations. The most relevant research on this topic is based on movie synopses and Latent Semantic Analysis (LSA) .However, the prediction power is far from satisfactory due to the relatively small average size of a recommendation. When applying Word to Vector (word2ec) methods on movie reviews, we witnessed a huge boost inperformance, and the results are mostly consistent with those of the Internet Movie Database (IMDB).
This article focuses on building a movie recommendation system (now deployed as web application). The following is a general view of the front end interface.
The website is now accessible through address is http://movienet.us-west-2.elasticbeanstalk.com/.
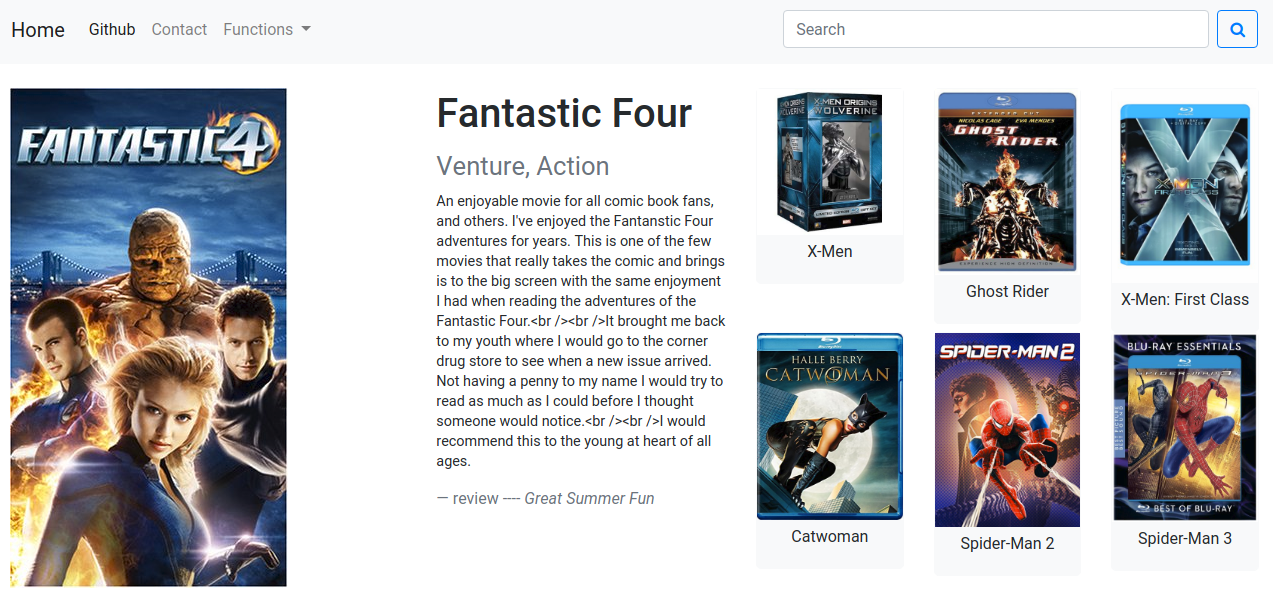

For the scope of the blog, we will be focusing primarily on the modeling aspect. For detailed code of the whole project refer to the Github folders, which includes code, documentation, and addendum instructions (additional tools for website building are available as well).
Github repository for website: https://github.com/pankh13/movienet
For model: https://github.com/pankh13/NLP_movie_recommender
Why NLP and Content-Based Filtering?
- First, let’s explore the reasons behind using content-based filtering.
Most of the Content-Based Filtering (CBF) methods are being outperformed byCollaborative Filtering (CF) due to the lack of meaningful information extracted from items (meta-information). We can think of the matrix generated by the meta information to represent the characteristics associated with the item in question (genre, tropes, tastes). Therefore, the robustness of the system is highly dependent on the granularity of the available meta-information.
For example, when running CBF on movies, the data we used to reconstruct this movie’s content is often limited to directors, actors, actresses and genres. This may work well in some cases, especially in a series of movies, but for a general use case, performance is not adequate. The movie is not a linear combination of those characteristics.
An alternative source of characteristics can be found in the form of audience reviews, who may have thousands of different opinions on a single movie., yet include some commonality that we may label as a ‘theme’.
It would represent a missed opportunity to not explore reviews as a possible data source.
We now introduce Natural Language Processing as a valid, new approach to reconstruct a movie’s unique fingerprint; i.e. find the hidden ‘theme’ inside movie reviews.
- Next we assess the effectiveness of NLP as a powerful and helpful tool for this goal.
The usefulness of natural language processing has arguably been due to the simple reason that it cannot be as precise as human being. It’s debatable how useful natural language processing can be due to the limitations of achieving human being levels of precision. However NLP finds utility when we process a large set of text data that it’s not financially feasible or impossible to be processed by a human. NLP allows us to extend our ability to structure intangible reviews into cognitively digestible information.
This is the case within movie data.
Human understanding outperforms algorithmic approaches when we know precisely a review’s meaning by connecting it with our own experience. However, machine learning approaches gain ground when processing tens of thousands of movies, since no human has enough time to watch them all.
Building a NLP CBF model for a recommendation system has other advantages, including:
- The marginal increase of space complexity is not significant. Although the initial model training will introduce a huge vocabulary set into the model, this increase slows down when the model reaches a certain size, which includes most of the frequently used words. This approach works well with those cases where the number of user is far more than that of products, e.g. movies, shopping websites.
- This model is applicable to products in different categories. For example, a well trained word2vec model can do the following calculation:
 This is of particular interest when we want to do cross-category recommendations.
This is of particular interest when we want to do cross-category recommendations.
Paragraph Vector
We now introduce the algorithm used—Word2vec. When constructing semantic correlation models in NLP, we generally use so-called word embedding: mapping words or phrases to numeric vectors. Those vectors represent the ‘meaning’ of the words through a mathematical representation. Among those word embedding methods, Word2vec is best for this case. Research has shown that Word2vec has a steep learning curve, outperforming other word-embedding techniques (e.g. LSA), when it is trained with medium to large corpus size (more than 10 million words)[2]. To note though that the best parameter setting depends on the task and the training corpus.
Word2vec is not really one model, it is a group of related models that are used to produce word embeddings. They are two-layer neural networks that take in text corpus for training, and use neighboring words to predict each other. Through training, a set of vectors are generated each representing a word [1].
Based on word2vec, doc2vec (Paragraph Vector) was designed in 2014. This model further develops word2vec by considering the feature of each document in the text corpus. The model takes in the tags (multiple, either unique or duplicate) in the input text corpus and generates a vector representing those tags as well.
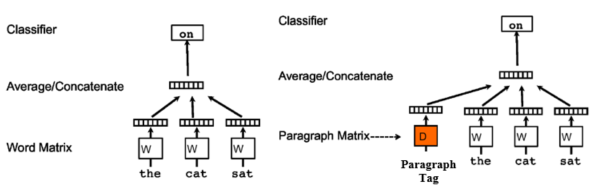
In a doc2vec model, we are going to use the movie reviews as the text corpus fed into the model and use the movie names as the ‘tag’, so that we can have a representation of the movie contents.
Data Collection & Data Cleansing
Special mention will now be made about data collection and data cleansing due to the rarity of available movie review data. The primary reason that most of the movie databases prevent web spider or API from accessing movie review data is for protection of the users’ privacy. The best dataset we could can find was Web data: Amazon movie reviews[2] published by J. Leskovec, which has ~8 million movie reviews up to October 2012. Reviews include product and user information, ratings, and a plaintext review. For further analysis, we had to use Amazon Advertising API to scrape down the movie names (and posters of course for building the website).
The unzipped file containing the data is more than 9 GB large. For reproducibility a database storage is strongly recommended due to the further steps required.
The first step was to dump data into a database and perform the initial EDA. To guarantee the precision of the model, only those products were selected with more than 175 reviews, cutting down the number of rows to ~4 million.
Second step was to scrap down movie name and movie poster data from Amazon. This required usage of Amazon Advertising API, which involves a standalone application request. To note is the API’s limit of 1 access/second, so special care should be taken in doing the grouping by ID first to save time and adding a time.sleep() when accessing it. Amazon does not specify whether this API is robot friendly. We leave further considerations to the reader.
The third step was to write those reviews and movie names needed back into file, since IO is faster than database access and saves a lot of time during training. This shortcut is easily applied, but order preservation is important. Filtering out those reviews that either too long or too short is also a necessary step. A final data adjustment step was needed on each review and will be discussed in the next section.
Model Training
Before training, there’re two things that require particular attention:
- Loading all the data into RAM should be avoided. It’s slow and even impossible for most PCs.
- Further formatting is needed on review texts.
- Get rid of stopwords. Stopwords are the set of words that don’t contain contextual meaning in a certain language, e.g. for English words like ‘the’, ‘a’, ‘and’.
- Remove special character.
- Convert to all lower case. (it is better since we are not distinguishing different terminologies here)
Then we can prepare our text data for model training. Use an enumerator to iterate over the data and create a ‘Labeled Sentence’ object to feed into doc2vec.

The actual training is straightforward compared to other work. In the newest version (different syntax might be found on other web tutorials, but this is for the latest version) you only need one line of code here. To make the training result reproducible, we need not only set the random seed but also fix the number of workers to 1, since the OS threading may introduce extra randomness.

Note that, if you don’t need your result to be reproducible you can use (import first) multiprocessing. This may save several hours depending on the processors and disk type of the machine.

After hours of waiting we will finally have the trained model. Load the model in and run queries. Similar to other neural network models, tuning the parameters is very important. During several iterations I found out that the number of epochs should be more than 10 for a stable performance, yet that other parameters didn’t have much of an influence. Below are some of the test results. (These were unfiltered so they include duplicate movies with different product names on Amazon)

The website has received positive feedback from my classmates. However, there is still room for improvement, e.g. the movie names are those being used in Amazon’s movie product catalog, which still remains messy despite the work I did; compare CBOW and skip-gram algorithm, etc.
Other Interesting Results
Once we finish building this model, we get several other topics to test on.
Predicting the movie described in a review: this is easy to understand; get the vectorized representation of a review and calculate the movie tag most similar to it. Take this review for ‘Star Wars Episode V’ for example:
This feature works well and the longer the review the better it performs.

Prediction of movie genre:
The idea is to calculate the ‘cosine distance’ between the movie vector and the genre vector. Get a list of genres and calculate which movie is closest to (working on this feature for improvements.)
Getting similar words:
This is one of the most important functions of the original word2vec model. However, in this model where only movie-related data is used, such kind of model could be biased. There’s also a test function (model.accuracy) built inside doc2vec (test dataset available from https://github.com/nicholas-leonard/word2vec). If a more precise model is necessary, we can always use this for optimization. (This variation of the model built by CBOW is terrible for this test, indicating it is not good enough for generalized usage.)
Reference:
[1] Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[2] Altszyler, E.; Ribeiro, S.; Sigman, M.; Fernández Slezak, D. “Comparative study of LSA vs Word2vec embeddings in small corpora: a case study in dreams database”.
[3] J. McAuley and J. Leskovec. From amateurs to connoisseurs: modeling the evolution of user expertise through online reviews. WWW, 2013.