| By Macon McLean ’16 |
Like all people with good taste[1], I have long been a fan of the Star Wars film series. Ever since witnessing the theatrical re-release of the holy triptych when I was a kid, I have marveled at the way George Lucas invented a living, breathing universe for viewers to enjoy.
Part of making such a universe feel fully-realized is developing a unique vocabulary for its characters to use, and the Star Wars movies pass this test with flying colors. The evidence is that nearly everybody who’s witnessed one of these adventures from a galaxy far, far away remembers the names of “Luke Skywalker” and “Darth Vader”, and can describe a “Jedi” or “the Force” with ease. These four examples are some of the Star Wars universe’s named entities, words or phrases that clearly describe certain concepts in a way that differentiates them from other concepts with similar attributes.
Named entities are used to inform the process of named entity recognition (NER), the process of automatically identifying and classifying these entities in a given corpus. This process can be used in creative and meaningful ways, like examining locations in nineteenth-century American fiction[2] for an analysis of named locations in literature[3]. It is often used as part of relation extraction, in which computers pore through large volumes of unstructured text information to identify possible relationships and record them in a standardized, tabular form. NER classifiers are computational models trained to support these efforts, minimizing the need for manual tagging by humans and preparing the data for inference. Consider the following sample sentence:
“Steve Spurrier played golf with Darius Rucker at Kiawah Island in May.”
Using just a few simple classes (PERSON, LOCATION, DATE) we can examine each word in the sentence and tag the named entities as follows (commas inserted):
“PERSON, PERSON, O, O, O, PERSON, PERSON, O, LOCATION, LOCATION, O, DATE.”
Tagged sentences like this one can then be used to train an NER classifier, helping it learn when and how to apply those three types of tags.
The downside of NER is that classifiers trained on the vocabulary of one domain do not generalize well to others. This makes sense, as the conditional random field[4] (CRF) at the heart of the classifier is a context-based method. The contexts surrounding named entities of chemistry differ significantly from those of named entities in economics, or Chinese literature, or Star Wars, so the CRF will train differently for each domain.
After learning all this, I began to imagine other uses for NER classifiers. One idea was to use it as a means by which to compare the vocabulary of a specific text with similar works, as a very specific kind of lexical similarity measure. Since these classifiers are so brittle, it would work only within a specific domain, and could only make very fine distinctions. After an exhaustive[5] search of the top journals, I did not find any examinations of a Star Wars-specific NER classifier. So obviously it became my mandate to train an NER classifier for the very necessary task of Star Wars named entity recognition via Stanford’s CoreNLP suite.
To train such a classifier requires a significant amount of legwork on the front end. You must create a training corpus with each word tagged as part of a class. For this research, I used the full scripts from Star Wars, The Empire Strikes Back, and Return of the Jedi. My corpus was tagged with eleven classes: other, person, location, duration, misc, date, number, organization, ordinal, time, and percent.
The procedure was fairly simple (albeit time-consuming). I first created a Python script that augmented the out-of-the-box NER classifier in the Stanford CoreNLP suite with user-input dictionaries. Ten of the above classes are standard, and I added the misc class to cover anything Star Wars-related that did not fit adequately in the pre-existing set of classes (e.g. vehicles, alien race names). Then I manually inspected each script and developed a few rules to keep tagging consistent across the three scripts[6]. After some final formatting, the training files were ready to go.
Using the CoreNLP training commands, I fitted a classifier to the text from both the original Star Wars (SW) and the Empire Strikes Back (ESB) for testing on Return of the Jedi (RotJ), then did this two more times for the other two possible configurations. I also ran the standard classifier on each script as a baseline for comparison. It turns out that in this case (perhaps due to small sample size), the out-of-the-box standard classifier only tagged my corpus three classes (location, person, organization), so I have broken those results out below. Each classifier is identified by the film it is tested on:

As expected, the trained classifier outperformed the standard one in each case. I have omitted the full table because the trained classifier was also better in each subcategory in each case. The average increase in precision was 18.84%, recall was 63.77%, and F1 was 55.32%[7].
Now let’s compare the performances of each of the three trained classifiers to one another. First, here’s the full breakdown:
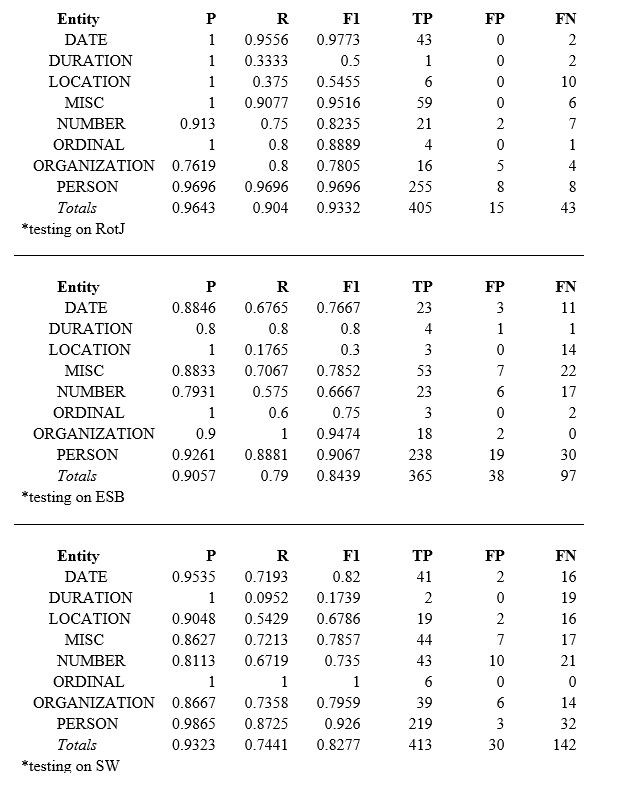
And now a graphical comparison of overall performance:

Finally, the same chart as above, but only using the four most domain-specific categories:

The model trained on Eps. IV and V and tested on Return of the Jedi leads the pack in precision, recall, and F-score both across all categories and on the subset of domain-specific terms. In fact, recall and F1 increase as we move forward in time with regard to the movie we test on (precision is actually second-highest for the model trained on V and VI). Precision is very good, with all but two figures higher than 80% (a decent helping of ones on the best model) and above 90% in the subset. Recall is also fairly impressive (except in location and duration, and only in the few cases where the number of relevant words was less than twenty), and above 80% across the board in the subset.
As good as they were, the preliminary results did have me somewhat concerned, so I decided to do some further investigation. I wanted to make sure that the model wasn’t simply regurgitating different words it had learned during training and just missing the ones that weren’t there. I needed to make sure that this model actually learned.
So I manually inspected the corpus again. According to my tags, Return of the Jedi has exactly thirteen instances of unique person-class words not seen in Empire or Star Wars. If it was just tagging previously learned words and missing the new, heretofore unseen terms, we would expect the total number of false negatives (missed words) to be at least thirteen in number. However, there are only eight, so we have good evidence that the model is really learning – at least five of the thirteen new words are being picked up by the trained classifier.
Repeating this analysis, there are thirty-one unique person-word instances in ESB and forty-one in Star Wars, so no pure regurgitation here either given the false negatives. However, when I looked at location and duration, the two fields that actually suffer from high precision and low recall, I saw that there is a chance it is simply repeating learned words – though false negatives are less than or equal to unique instances in most, there are more false negatives than my tabulated number of unique location-words by one for Empire and by two for unique duration-words in Return (though these suffer from notably low sample size).
The bottom line? Star Wars stands out as the film with the named entities least recognizable by a classifier trained on its two sequels, according to F1-score. Empire is pretty close behind, and Return’s named entities are most easily classifiable by a longshot. This is true both across all categories and the four-class subset.
But why? One hypothesis is that Star Wars has significantly more named entities than the other two, which results in more chances for misclassification. However, this fails to account for the similar performance of Empire. Another (and in my opinion the more likely) explanation is that it is an artifact of the order of the films. When the classifier has trained on Star Wars and Empire, it can refer to any context learned in those films when studying Return; this is ostensibly far more useful for classification than when the converse model refers to temporally subsequent contexts to classify terms in Star Wars. Of course, there could very well be a third explanation I’m missing entirely.
One way to help decide this is to expand this analysis to the prequel trilogy. Unfortunately, I’m not sure I can spend the requisite hours tagging the script for Episode II without losing my mind[8]. Until I can, I’ll just have to try to tap into the Force to figure it out.
[1] Though this is the subject of some debate, let’s just treat it as fact for this exercise.
[2] A pseudo-tutorial by the textual geographies people: https://blogs.nd.edu/wilkens-group/2013/10/15/training-the-stanford-ner-classifier-to-study-nineteenth-century-american-fiction/
[3] The greater textual geographies project: http://txtgeo.net/
[4] For a solid introduction to conditional random fields, check out this blog post by Edwin Chen: http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
[5] The search was admittedly less than exhaustive. But I doubt there’s anything else out there.
[6] I found myself thinking I could write a whole paper about this task alone. Whenever possible I tried to use common sense. This is a nuanced task and instituting different rules might well have yielded somewhat different results.
[7] For an explanation/refresher on the differences between precision, recall, and F1 score, it’s hard to beat the Wikipedia page: https://en.wikipedia.org/wiki/Precision_and_recall
[8] Episode II is the weakest link. Search your feelings, you know it to be true!