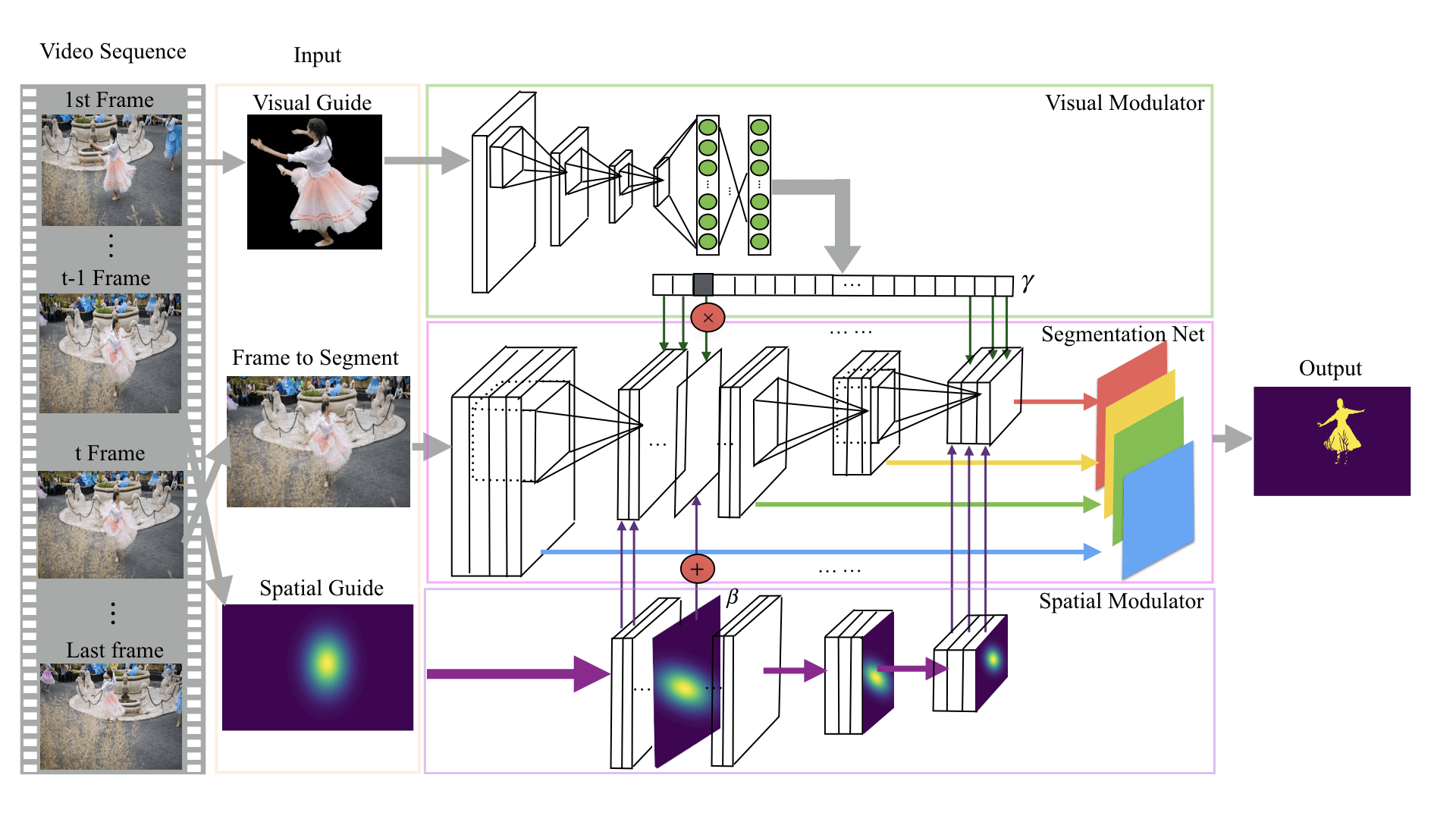
 In image and video segmentation domain, the proposal of one shot learning contributes greatly to image segmentation. Traditional one shot learning updates the weights of the whole model to guide it towards a target object. Unfortunately, this technique has very limited practical use both in terms of computational cost and strict memory demand. In this paper, we present visual and spatial guide modulators (VSGM), an add-on component of a general segmentation network, that is specifically designed to eliminate the shortcoming of traditional one shot fine-tuning. VSGM allows for quick adaption over a segmentation net towards a target object by creating a surprisingly simple layer-wise transformation. The layer-wise transformation consists of scaling and shifting operations on each feature map of the model. Although VSGM is generalized to any fully convolutional networks (FCN) based applications, this paper focuses on semi-supervised video segmentation problem. We show top performance compared against eight state-of-the-art semi-supervised video segmentation methods covering both real time and non-real time approaches on three recently released datasets.
In image and video segmentation domain, the proposal of one shot learning contributes greatly to image segmentation. Traditional one shot learning updates the weights of the whole model to guide it towards a target object. Unfortunately, this technique has very limited practical use both in terms of computational cost and strict memory demand. In this paper, we present visual and spatial guide modulators (VSGM), an add-on component of a general segmentation network, that is specifically designed to eliminate the shortcoming of traditional one shot fine-tuning. VSGM allows for quick adaption over a segmentation net towards a target object by creating a surprisingly simple layer-wise transformation. The layer-wise transformation consists of scaling and shifting operations on each feature map of the model. Although VSGM is generalized to any fully convolutional networks (FCN) based applications, this paper focuses on semi-supervised video segmentation problem. We show top performance compared against eight state-of-the-art semi-supervised video segmentation methods covering both real time and non-real time approaches on three recently released datasets.
For more details, please refer to link