| By Daniel Lütolf-Carroll and Rishabh Joshi |
Problem Statement
Deep Learning has been applauded for its versatility and applicability on many use-cases across industries. We set out to explore and familiarize ourselves with DL on a problem that was relatable to most: video streaming. Our project aimed to enhance the user viewing experience by improving advertisement allocation to videos through activity classification of segments within a video. The underlying assumption is that users viewing a video centered around a human-relatable activity are often interested in the context, information, or even industry pertaining to the activity and would be receptive to advertisements associated with the activity.
The focus of our classification was therefore on isolated activities within a video. Our approach involved classifying images at a frame level, while also exploring ways of incorporating temporal information from the frames, so that advertisement can be fine-tuned even for videos with complex activities or a variety of themes that evolve over time. We developed deep learning models following different strategies to see what works best for identifying activities in videos.
Dataset
The dataset used is the UCF101 (crcv.ucf.edu/data/UCF101.php) from University of Central Florida Center of Research in Computer Vision. The dataset is composed of 13,320 videos labeled in 101 action categories of 5 types: Human-Object Interaction, Body-Motion Only, Human-Human Interaction, Playing Musical Instruments, and Sports. Figure 1 shows the classes of activities.
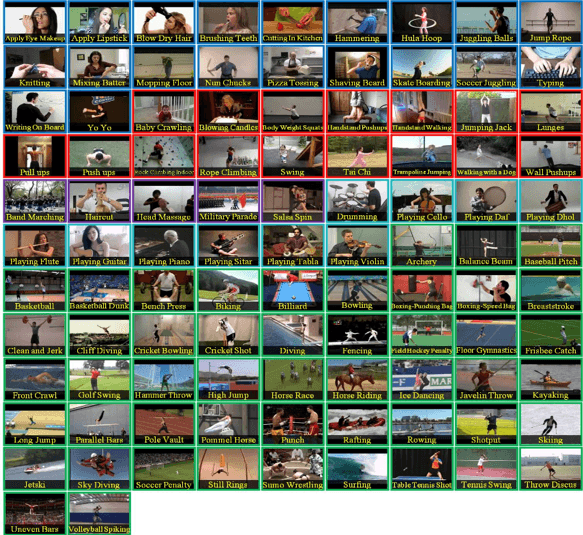
Most videos are between 4-10 seconds long and present an ideal training set to generate models that can capture individual actions. Although the videos vary in terms of quality, background, lighting and other contextual variations, the labeled activity category they belong to is well defined. After examining the dataset closely, our group decided that the UCF101 contains the ideal balance between strong features for activity classification of a video with enough noise and variation to be generalizable to other YouTube or online streaming videos. Videos are about 320×240 in resolution with 25fps (total bitrate ~340kbps) and are representative of the low quality frequently found online. However, in terms of visual information from the perspective of a human, there is little difference between a 1080p or 240p video for the sake of recognizing the contained activity, so the resolution was considered adequate for the project’s scope.
For each activity category there are 25 groups of videos, each representing a set of videos spliced from an original. Therefore, videos in the same group will have similar contextual variations (e.g. same background, actor, angle, lighting). Figure 2 shows examples of fencing and drumming images extracted from the training set.

Overall, our team was strongly satisfied with the dataset, given its diverse set of actions taken from daily unconstrained environments. Each action in the dataset is taken from different angles, giving us more power to correctly predict movements and actions in a realistic setting. This allowed us to evaluate the model using videos we recorded personally.
Technical Approach
Model training
Videos are sequences of static frames. To classify a video, it was important to analyze the frames in the videos. We extracted images from the videos using the ffmpeg codec. We generated images at around 30 Hz for each video. The next major steps were to represent these frames using some visual features and finally, classify the video based on the features generated for multiple frames in the video. We explored four major approaches by following different strategies for these steps, namely, Multi-layer Perceptron (MLP), Recurrent Neural Network with Long Short Term Memory units (LSTM), Long-term Recurrent Convolutional Networks (LRCN), and a 3D Convolutional Neural Network (Conv3D), as shown in Figure 3.

The first step was to split the videos into train and test sets, keeping in mind that videos from one group must not be present in both train and test sets, since that would result in overfitting. Fortunately, UCF offers lists of varying ratios to facilitate the data splits into train and test sets. After that we extracted frames from each of the videos at 30 frames/second, but downsampled to 40 frames per video at uniform intervals, irrespective of the duration of the video.
Next each of the 40 frames are fed into a convolutional neural network (InceptionV3, with the first half of the layers frozen, and the latter half fine-tuned) and treating the output of the convolutional layers as the feature representation of the frames. The InceptionV3 was fine-tuned by classifying the frames independently with the same labels as the videos themselves. This is referred to as the CNN model in Figure 3.
These 40 list of features are then concatenated and passed to a fully connected network (the MLP model) for classification. The 40 list of features could also be treated as a sequence and passed to an LSTM model for classification. This would incorporate the temporal flow of information in a video, resulting in better classification results. The disadvantage of these two approaches is that it trains the Inception network independent of the MLP and the LSTM model.
To overcome this, we tried training the convolutional part and the LSTM part of the neural network together from scratch (making the training process extremely long and slow). This model is called a Long-term Recurrent Convolutional Networks (LRCN). Since, we are using LSTM units in the model, we had to use Keras’ time-distributed 2D convolutional layers before the LSTM layers so that we can apply the same convolutional layers to all the 40 frames. This makes the 2D convolutional layers behave like RNN layers. We followed a VGG-like structure to build the time-distributed 2D convolutional base.
The final approach we tried was to use a 3D convolutional neural network (Conv3D) instead of a 2D one, by adding time as the third dimension. This would allow us to feed all the 40 frames of a video at the same time to the network. This approach, same as LRCN, required high computational resources since there are many more parameters to tune. The architecture of this model was also similar to that of the VGG network.
For our optimizer in all the above models, we found Adam to work most efficiently, which is what we ended up using. Alternatively, RMSProp yielded results coming in as a close second. We also ensured to make use of dropout layers wherever necessary with 0.5 dropout.
Model application on new videos
New videos to classify are first processed to frames at 30fps. To generate a real-time classification score, instead of downsampling to 40 frames per video, all frames from the test video are kept. Next, the frame features are generated by feeding the video frames to the fine-tuned InceptionV3 network. For every one second of the video, we send the latest consecutive 40 frames to the final model and get the classification scores. Namely, we generate the classification scores on each video clip of length 1.33 seconds, and the score was updated every one second.
As a product demo, we used OpenCV library in Python to add the real-time scores to test videos. Top five classes and their corresponding probabilities are shown (as the screenshot in Figure 4).

Results
The CNN model, driven purely by visual features, performed with 60% accuracy (top 1 class), which is significantly higher than random guessing at 0.9% accuracy. By incorporating temporal aspect of frames to classify the video category, the model accuracy was increased to around 70% for both LSTM and MLP. Adding temporal features yielded improvement; however, comparing our models highlights how visual features played the most important role when gaining quick improvement at low cost of complexity. The LRCN and the Conv3D models performed surprisingly poor, which might be due to lack of computing resources and time. These results are presented in Figure 5.
Within each approach, we trained the model until there was no change in the training loss for 5 consecutive epochs or when we saw an overfitting trend based on train and test loss curve. After getting the best model for each approach, we used top 1 and the top 5 accuracies to choose the overall best model. The top k accuracy is defined as the proportion of test cases where the actual class was present in the top k most probable classes predicted by the model. The LSTM model is better in terms of top 5 accuracy and the MLP is better in terms of the top 1 accuracy.

Analysis of Results
Based on the performance of our models, we tried to find the classes which were the easiest and hardest to classify for the models. Figure 6 shows some easy (Writing on the board), medium (Brushing Teeth) and hard (Tai Chi) examples to classify. This is primarily due to the first being the only activity where a human reaches out to a wall with their hands, while the latter two containing movements that aren’t very distinct relative to other classes. Brushing teeth involves the acting agent using their hands in the facial area, which overlaps with activities like Applying Makeup or Lipstick. In the case of Tai Chi, it is arguably hard even for a human to classify without context.

When we tried to combine two classes, for example, doing Tai Chi but near a tennis court (we got one of our team members to try this out), our model failed to classify the correct class (Figure 7).

In this example, we ideally wanted the model to label the video as Tai Chi, but it instead labeled it as a Tennis Swing. We saw that the filters picked up the tennis court in the background (Figure 8) which might have misled the model.

Additionally, we took a few videos of ourselves doing Tai Chi indoor and the model did not predict the correct class. The main reason why we think this happened was that we saw most of the videos in the Tai Chi category were taken in a park with a lawn in the background. Our model may have focused more on the background instead of the movement and gesture for this specific class. Overall caution should be placed when attempting to model large varieties of activities, because while increasing the number of activity classes will ensure more versatility of said model, it will also inevitably reduce the distinctness between each activity class.
Concluding remarks and future work
The trade-off between a parsimonious model with high levels of transparency but low performance, versus a complex model with high accuracy but lack of transparency is a topic of constant debate. If a model is designed to help generate inferences that can be further explored for business values then the priority should be shifted towards the former, but if performance is mostly of concern, the latter should be deployed, as long as the assumptions pertaining to model structure and process are transparent enough to be validated. In our project we found that some classes performed incredibly well, because the model was picking up features that weren’t necessarily connected to the activity, but an artifact of data dependency or poor training variations (e.g. background grass on all our Tai-Chi videos). If data selection, treatment, and training are performed rigorously, then even if the exact nature of the features isn’t perfectly understood the results should still be trusted on the basis of sound methodology and model robustness.
Our original intent going into the project was to develop a proof of concept (PoC) that could later be extended for commercial use. Although we believe our methodology, data preparation, and model architecture are well suited for a final product, the biggest bottleneck is the limited amount of classes and variations within each class that we used for training. Our final revised model can be deployed (with a few more optimizations) with the understanding that it’s limited to only a small subset of specific activities. This might not be a limitation for advertising purposes that involve products that fall within our categories, but for general purpose use the model would have to be extended drastically. The UCF101 dataset primarily contains human-centric sports activities that make it interesting to model as a PoC, but that restricts its use to advertisements that revolve around sports or physical activities. Extending the dataset further would help address the business value of the model, but would also bring into question the validity or results of our approach: it is hard to speculate how well our model would perform given 1000+ classes.
A more realistic alternative would be to develop parallel models on different classes and run them in tandem. Having each model try to find or classify different categories of activities would deliver greater business value. Another idea would be to develop one model that categorizes the type of video (human, non-human, out-doors, in-doors, etc.) and then have type-specific models be selected depending on the need. Either way by working on the problem we are certain that a Deep Learning approach outperforms more traditional methods in this area; currently many streaming services label videos according to an uploader’s self-reported categories or through naive algorithms that look for visual or auditory cues (often associated with the background music).
To extend our project to a finalized product performance, class flexibility, high accuracy, and training speed would all be factors to improve on. The rate of constant new content being uploaded to streaming services is high, so converting raw footage for prediction purposes in a timely manner would certainly be highly desired. Additionally, new types of activities would arise at a constant rate (social or media trends) that would have to be included in training or dealt with in an appropriate manner. Exploring the use of parallel tandem models, or the use of stacking/ensembles of models would be our best suggestion to extend the project further.
References
[1] Khurram Soomro, Amir Roshan Zamir and Mubarak Shah, UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild., CRCV-TR-12-01, November, 2012.
[2] Five video classification methods implemented in Keras and TensorFlow from Matt Harvey
[3] http://www.deeplearningitalia.com/wp-content/uploads/2017/12/Dropbox_Chollet.pdf
Acknowledgments
The project was related to our deep learning course work and carried out by Shih-Chuan Johnny Chiu, Yifei Michael Gao, Rishabh Joshi, Junxiong Liu, Daniel Lütolf-Carroll and Hao Xiao. We’d like to especially thank Dr. Ellick Chan for the support and guidance during the project, as well as all the other people that contributed with insights and feedback.