| By Dr. Ellick Chan |
MSiA students are helping lead the way toward building more reliable deep learning AI models by making them explainable. This Spring, 9 student groups developed ways to “peek into” models built for their projects. In previous years, students were able to do impressive work in their projects, but they were often left wondering why a model behaved the way that it does. The lack of explainability or interpretability raised some deep questions about the inner workings of their models, and that poses a barrier to adoption in safety-critical industries such as automotive, medical or legal.
This year, the students utilized several methods to show the “visual attention” of their models. Through this process, they were able to better understand how the model arrived at its prediction and as a result gained extra confidence in the model’s thinking process. This work parallels early studies in human attention performed by Yarbus, et al whom showed that human eyes fixated in different areas depending on tasks. The students found that machines can also behave similarly when classifying images, and students were able to leverage this insight to better understand how the machine was perceiving images to build more robust models that perceive the world more like how humans do.
We believe that this work is a helpful first step in making model interpretability and understanding a core component of deep learning analytics education. Machine learning today is very much a black-box art, and in order to gain wider acceptable in society and trust in the model, we must emphasize the need to peek into such models to see how they operate and what the limitations of the model may be.
For more information on our efforts to understand deep learning models, please view an overview presentation here. Course slides are available here.

Yarbus study of human gaze in a scene – (Left) original painting, (Middle) estimate the age of people in the room, (Right) remember clothing worn by people. Note how the gaze patterns depend on the task at hand.

Machine attention maps of ballet positions. Top row shows the attention map with white denoting areas of interest. Bottom shows a masked version of image. Note how PenchPonce is characterized by one leg up in the air. The machine attention map agrees with what a human observer would look for to classify this move.
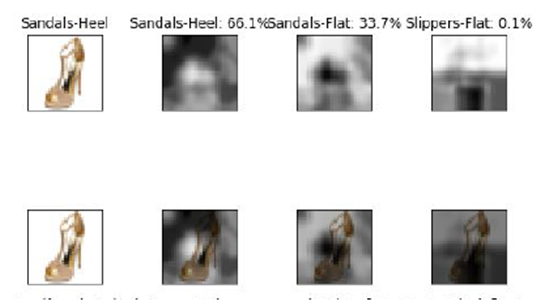
Machine attention map for shoes. Note how the heel class is characterized by the higher heel and loop.