| By Jeff Parker |
I was so impressed to learn from a peer that computer programs have been written to compose music. Music is widely considered an art that takes innately human abilities to craft pleasing sounds. Computers are dull and inanimate while music is alive and human. I do not have a musical background, but after investigating this “artificial” music, I realized that the programs analyze sounds and patterns to piece together new compositions.
So if computers can compose music, something so deeply personal and human, I thought, what else deeply personal can they do? An idea sparked when I asked my wife late at night to tell me her favorite scripture verse in lieu of reading a chapter as is our nightly custom. My wife was too sleepy to read, in her drowsy voice gabbled what sounded like a random assortment of the most common biblical words, “For behold, thus sayeth the Lord, verily I say unto thee, that…” It was hilarious, but to the untrained ear, could have passed as a legitimate passage.
The English language, much like music, follows certain patterns – any English major would agree. There are subjects and predicates instead of tunes; nouns and verbs instead of notes. The language of the ancient Jewish, Greek and Roman authors as translated by English monks certainly follows a very distinct pattern. Many bible scholars and linguistic experts have written much on this. I thought I might try my hand at using a computer to “artificially” write scripture.
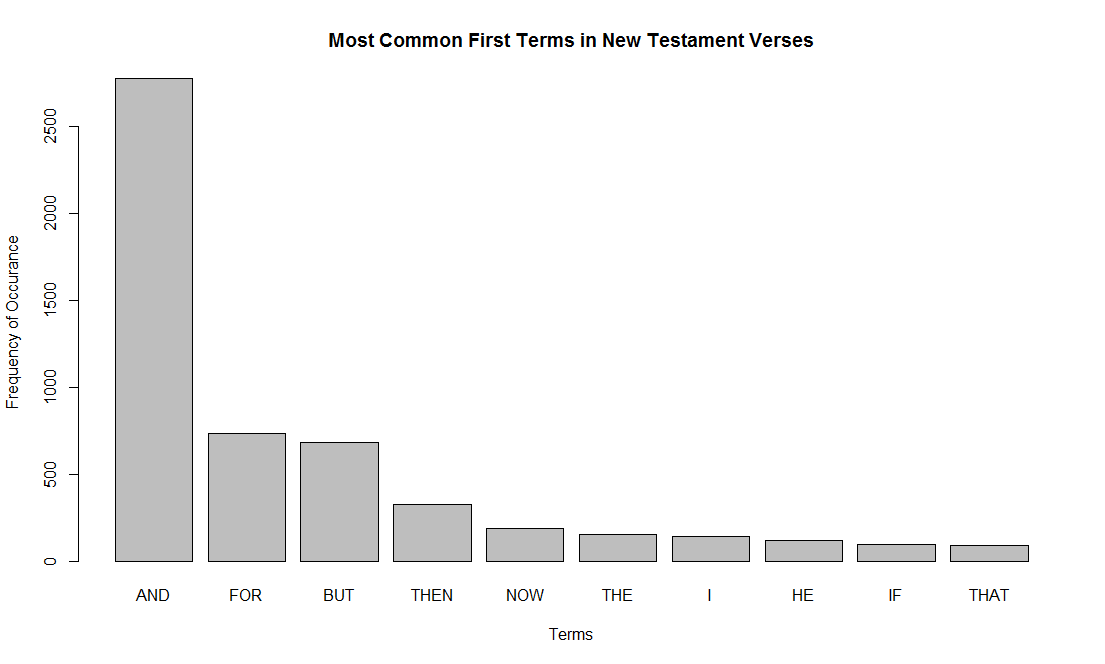
I should note that the Bible is something that is deeply personal and intimate for many people (as is music). For others, it is a very divisive subject. My humble attempts here are not to make a mockery of the Bible or to advocate it, but rather just to explore linguistic patterns using a scientific process. Wherever you fall on a religious spectrum, I think much can be learned from this type of text analysis. For instance, there are 5,975 unique words in 7,958 verses in the King James Version of the New Testament. I decided to focus solely on the New Testament, because 1) it is more recent, 2) it takes place over a shorter period of time than the Old Testament and 3) it is both shorter for computing purposes and easier to understand. All my R code can be found here. Below are the most common terms in the New Testament (“the”, “and”, and “that” are excluded):

Just using the most common words, I can manually piece together something that sounds like a scripture verse:

Approach 1 – Subsequent Terms
I decided on three approaches to craft my “artificial” scripture. The first is to pick a first word (a seed word) and calculate which word is most likely to follow that. Then the word most likely to follow that word. And so on till something makes sense.
Using the second most common starting term “FOR” I started down a path till I got the following: “FOR THE LORD JESUS CHRIST…” At this point, the most common word following CHRIST is JESUS which would put the verse into an infinite loop. So I choose the second most common word following Jesus. I had to do this a few times. Here is my final verse:
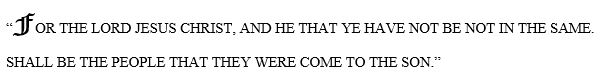
Not too bad. It is fun to see how the verse wanders down different paths. However, the biggest problem with this method is that the next word is solely dependent on the previous word. The subsequent words have no memory of previous words. If I was to add a bit of memory to my algorithm to account for phrases, our verse would have wandered down a different path. This memory could be added by using the preceding two words instead of just one. The word following “THAT THEY” is “SHOULD” and would have taken the verse in a different direction. It would be fun to write an algorithm to look at the two preceding words (the two nearest neighbors from K-NN techniques). I would also like to try a decaying weight on the preceding words (similar to kernel weighting regression).
Approach 2 – Market Basket
This idea is to use rule associations used in market basket analysis to find words that commonly appear in the same verse. Again after picking a seed word, I will find the word that is mostly likely to appear in the same verse. Then take the second word and find the word most likely to appear with that word. So on and so till I have a good collection of words. Then I will manually arrange them into something that looks like a verse.
The first step to this is to convert my data into transactions and look at some rules. This graph looks at the words that appear in 10% or more of the verses, or in market basket parlance, support greater than 10%.
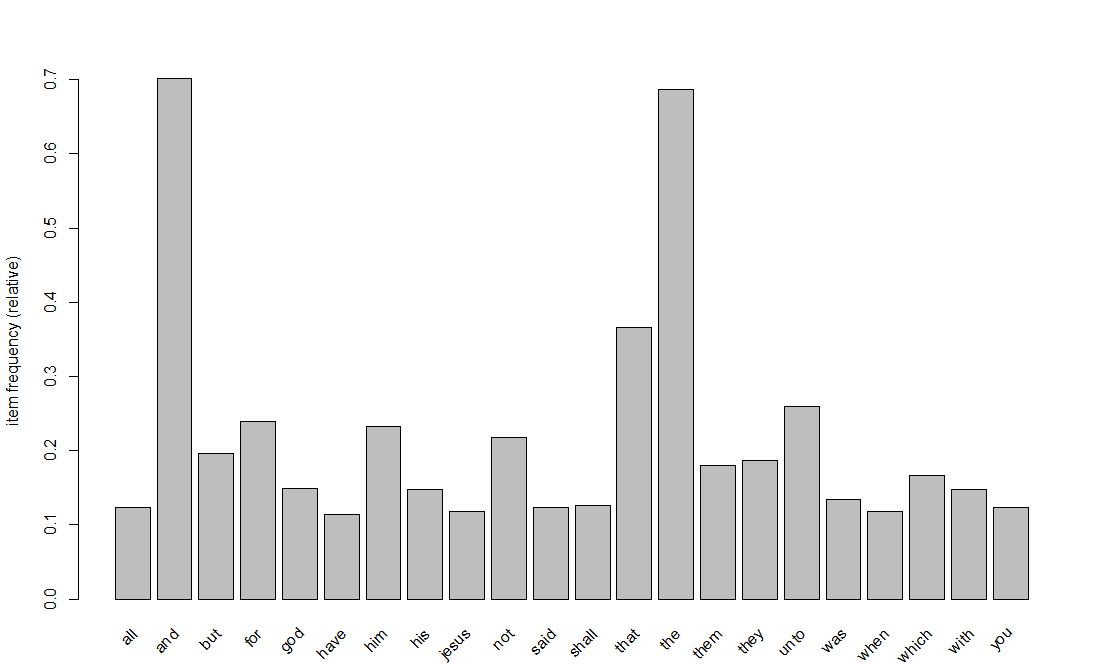
Market basket analysis looks at sets, so we if we expand the sets to several words, we get some great conglomerates of words that occur often together in a verse. I looked at sets of words with high support, here are few that stuck out to me:

My next step is to pick a seed topic and find words around that topic. Using the same seed word as in approach 1, I started with “FOR”. The word pair with the highest support with “FOR” is “THE”… No surprises there. I hit an infinite loop when I got to the word “THAT” so I skipped to the next highest support. In fact, {and,that,the} have very high support. Below you can see my chaining:
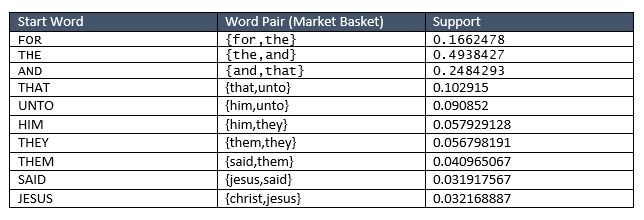
Now manually putting my words together:
![]()
Honestly, I was a little disappointed with this method. I tried this pattern using other seed words as well. A major drawback to the association rules is that sentences are sequenced while market baskets are not. The market basket calculates the most commonly used words in a sentence, whether the word came before or after, it does not discriminate. So this method does not capture the natural pattern of speech.
Approach 3 – Deep Learning
My last approach is to use deep learning techniques to generate the text. I have much to learn about deep learning, but fortunately, my professor, Dr. Ellick Chan, pointed me to some code on GitHub that students had used previously to generate song lyrics. I did not write any of the code, I just used it straight out of the box, but using the same New Testament as the corpus. Just for fun, I started run epochs before my wife and I went to church, and then I checked it when we got home. Here are some of the best results using the seed “not into the judgment hall, lest they s” which was randomly generated as part of the code:

I am really excited to learn more about deep learning and start playing with the code. The code actually generates based on individual characters. It is pretty remarkable that it generates actual words. However, I would like to change it so it uses words instead.
Conclusion
My intuition going into this exercise was that my approaches would get progressively better. I thought Approach 3 (Deep Learning) would do better than Approach 2 (Market Basket) which would do better than Approach 1 (Subsequent Terms). As a human reader you can be the judge, but personally, I think Approach 1 did the best. This is because this method captured the sequenced patterns of sentences (a noun is followed by a connector which is followed by an adverb, etc.). It think with some tuning the Deep Learning approach could also return some more interesting results.
Ultimately, after this exercise, I learned a lot about text analytics and a little about the New Testament as well. It was very entertaining for me to read and generate the scriptures. I am excited to see what other deeply human concepts computers can mimic in addition to writing scripture and composing music.
No Comments